Nowe przewagi konkurencyjne - technologia, informacja, społeczność
|
|
|
- Wanda Kołodziejczyk
- 8 lat temu
- Przeglądów:
Transkrypt
1 Seminarium Nowe przewagi konkurencyjne - technologia, informacja, społeczność Bogna Zacny Warszawa,


2 Zespół Wydział Informatyki i Komunikacji Katedra Inżynierii Wiedzy Agata Berdowska Krzysztof Kania Tomasz Staś Bogna Zacny
3 WYKORZYSTANIE INFORMACJI W KREOWANIU PRZEWAGI KONKURENCYJNEJ
4 Agenda Wykorzystanie informacji w kreowaniu przewagi konkurencyjnej gospodarka oparta na wiedzy informacja jako źródło przewagi konkurencyjnej Big Data
5 Dane, informacja i wiedza Dane reprezentacja obiektów świata zewnętrznego, dobranych w celu zapamiętania faktów, zdarzeń, prawidłowości. Przedstawionych w sformalizowanej postaci, umożliwiającej przekazywanie i dokonywanie na nich różnorodnych czynności przetwarzania
6 Dane, informacja i wiedza Informacja (teoria jakościowa) oznacza znaczenie, treści jakie przy zastosowaniu odpowiedniej konwencji przyporządkowuje się danym. Informacja ustala znaczenie danych w relacji do wyspecyfikowanego kontekstu działania lub wypowiedzi
7 Dane, informacja i wiedza Wiedza wykracza poza informacje, gdyż implikuje zdolność do rozwiązywania problemów, do inteligentnego zachowania i działania. To usystematyzowana informacja, będąca wynikiem celowego nagromadzenia lub wypadkową doświadczeń w odniesieniu do poszczególnych obszarów działalności.
8 Dane, informacja i wiedza Dane Informacja Wiedza Fakty, liczby, tekst Znajomość rzeczy Zdolność do efektywnego działania
9 Gospodarka oparta na wiedzy Gospodarka Oparta na Wiedzy (Knowledge Based Economy) Nowa gospodarka (New Economy), Gospodarka cyfrowa (Digital Economy) Gospodarka sieciowa (Network Economy)
10 Gospodarka oparta na wiedzy Podstawowe znaczenie we współczesnej gospodarce odgrywają nie tylko czynniki materialne (hardware, zasoby finansowe), jak to było do tej pory, ale w coraz większym stopniu wiedza. Wiedza: kodyfikowana niekodyfikowana Paul Michael Romer
11 Rodzaje wiedzy Wiedza ukryta (Tacit) Wiedza z doświadczenia Wiedza przejawiająca się w zastosowaniu Wiedza analogowa (praktyka) Przykład: Umiejętności manualne Wiedza jawna (Explicit) Wiedza z wnioskowania Wiedza którą można wyrazić Wiedza cyfrowa (teoria) Przykład: Formuła matematyczna
12 Zarządzanie wiedzą cechy wiedzy Cechy odróżniające wiedzę od innych zasobów (Alvin Toffler) Dominacja - wiedza zajmuje priorytetowe miejsce wśród pozostałych zasobów, ma ona strategiczne znaczenie dla funkcjonowania każdego przedsiębiorstwa; Niewyczerpalność - oznacza to, że wartość zasobów wiedzy nie zmniejsza się gdy jest przekazywana;
13 Zarządzanie wiedzą cechy wiedzy Symultaniczność - wiedza może być w tym samym czasie wykorzystywana przez wiele osób, w wielu miejscach jednocześnie; Nieliniowość - brak jednoznacznej korelacji pomiędzy wielkością zasobów wiedzy a korzyściami z tego faktu wynikającymi. Posiadanie dużych zasobów wiedzy nie decyduje bezpośrednio o przewadze konkurencyjnej.
14 Zarządzanie wiedzą Zarządzanie wiedzą to ogół procesów umożliwiających: tworzenie, upowszechnianie, wykorzystywanie wiedzy do realizacji celów organizacji.
15 Fazy modelu procesowego Pozyskiwanie Adaptacja Tworzenie Nabywanie wiedzy Gromadze nie wiedzy Przechowywani Kodyfikacja Wykorzysta nie wiedzy Wizja Technologie Produkty/usługi Dzielenie się wiedzą Transmisja Absorpcja
16 Big Data cechy Jedną z charakterystyk, jest zaproponowany przez Doug a Laney a z firmy Gartner w 2001 roku, model 3V Variety Volume Velocity
17 Big Data cechy Volume (objętość), który oznacza gigantyczny przyrost danych w bardzo szybkim tempie.
18 Big Data cechy Velocity (szybkość przetwarzania), rozumiana jako szybkość napływu danych. Ciągły napływ danych jest nazywany strumieniowym. Jakakolwiek interakcja lub przeanalizowanie danych napływających strumieniowo w czasie rzeczywistym wymaga ogromnej mocy obliczeniowej. Taką moc udostępniają nowe rozwiązania technologiczne na przykład farmy serwerów czy chmury obliczeniowe
19 Big Data cechy Variety (różnorodność), oznaczająca, iż zgromadzone dane zostały uzyskane z wielu różnych źródeł i są zapisywane w różnych formatach o niejednorodnej strukturze. Dane posiadające określony typ i format to dane strukturalne (structured), dane które posiadają tylko elementy struktury wewnętrznej nazywane są semistrukturalnymi (semi-struktured) oraz dane nie posiadające żadnej struktury noszą miano niestrukturalnych (unstructured).
20 Big Data cechy Firma IBM, która oprócz atrybutów wymienionych w modelu 3V dodatkowo uwzględniła cechę Veracity czyli wiarygodność. Atrybut ten oznacza konieczność weryfikacji pozyskiwanych danych. Należy uwzględnić fakt, że dane umieszczane w Internecie przez użytkowników nie zawsze są prawdziwe, co w konsekwencji wpłynie na nieprawdziwość wysuniętych wniosków.
21 Big Data cechy Istnieje również model 5V z atrybutem Value (wartość), ponieważ przetwarzanie BIG Data zmierza w swej istocie do uzyskania pewnej wartości - takiej wyjątkowej i nieznanej wcześniej wiedzy która zostaje wydobyta poprzez analizę dużych i złożonych danych i która może być wykorzystana do osiągnięcia jakiejś korzyści.
22 Co może być taką wartością? Dzięki możliwości automatycznego monitorowania treści opinii internautów w serwisach społecznościowych, automatycznej analizy treści e- maili, blogów ogłoszeń, ocen klientów pozostawianych na portalach aukcyjnych i w serwisach porównujących ceny itp., śledzenia przedmiotów włączonych w Internet Rzeczy, przedsiębiorcy wzbogacą swą wiedzę na temat:
23 Co może być taką wartością? postrzegania ich produktów, usług, organizacji przez klientów, opinii klientów na temat kampanii reklamowych i sponsorskich, reakcji klientów i kontrahentów na nowe produkty lub zmiany w produkowanym asortymencie, oczekiwań klientów co do rozwoju i kierunków doskonalenia produktów firmy, opinii kontrahentów na temat organizacji, interakcji pomiędzy kontrahentami.
24 Skąd bierze się wartość w BD? Jednym z podstawowych sposobów odnajdowania zależności pomiędzy zjawiskami oraz opisu rzeczywistości są metody drążenia danych (Data Mining).
25 Drążenia danych automatyczne odkrywanie nietrywialnych, dotychczas nieznanych, zależności, związków, podobieństw lub trendów - ogólnie nazywanych wzorcami (patterns) - w dużych repozytoriach danych.
26 Drążenia danych Statystyka Data Mining Uczenie maszynowe AI Bazy danych
27 Zadania drążenia danych Regresja Analiza wariancji Regresja prosta Analiza dyskryminacji Regresja logistyczna
28 Zadania drążenia danych Redukcja wymiaru cech analiza czynnikowa (analiza składowych głównych), skalowanie wielowymiarowe, analiza korespondencji analiza skupień. Grupowanie Hierarchiczne Niehierarchiczne (iteracyjno-optymalizacyjne)
29 Zadania drążenia danych Klasyfikacja Drzewa klasyfikacyjne i regresyjne Algorytmy reguł decyzyjnych Sztuczne sieci neuronowe Asocjacja Analiza koszykowa Analiza wzorców sekwencji
30 Analiza regresji Zbiór metod wykorzystywany do: oceny oczekiwanej wartości zmiennej y w oparciu o wartości zmiennych objaśniających X, oceny współczynników b, oceny poprawności i dopasowania modelu (funkcji regresji). y zmienna ilościowa, x 1, x 2,, x k zmienne ilościowe lub jakościowe.
31 Zmienna y Gdy zmienna y nie jest zmienną ilościową nie można stosować metod regresji liniowej.
32 Analiza dyskryminacji Metoda regresji stosowana gdy zmienna objaśniana (y) jest zmienną nominalną. Analiza funkcji dyskryminacyjnej jest stosowana do rozstrzygania, które zmienne pozwalają w najlepszy sposób dzielić dany zbiór przypadków na występujące w naturalny sposób grupy.
33 Regresja logistyczna Metoda regresji stosowana gdy zmienna objaśniana (y) jest zmienną binarną Cecha jest zmierzona na skali dychotomicznej (przyjmuje tylko dwie wartości).
34 Redukcja wymiaru cech Istotą metod redukcji wymiaru cech jest fakt istnienia silnej korelacji pomiędzy zmiennymi, które w rzeczywistości mogą mierzyć to samo zjawisko tylko z różnych punktów widzenia.
35 Redukcja wymiaru cech Celem metod redukcji wymiaru jest: zmniejszenie liczby elementów opisujących, wyeliminowania ze zbioru danych zmiennych silnie (funkcyjnie) zależnych od innych cech wybranych do budowy modelu, stworzenie struktury pozwalającej na przejrzystą interpretację zmiennych ukrytych.
36 Metody redukcji wymiaru Wyróżnia się wiele metod redukcji wymiaru przestrzeni cech: analiza czynnikowa (analiza składowych głównych), skalowanie wielowymiarowe, analiza korespondencji analiza skupień grupowanie cech.
37 Analiza czynnikowa pozwala na zidentyfikowanie nieskorelownych liniowych kombinacji zmiennych, użytych do celów budowy modelu gdzie każda zmienna jest wyjaśniana przez czynniki.
38 Skalowanie wielowymiarowe W analizie czynnikowej podobieństwa między obiektami (np. zmiennymi) są wyrażone w postaci macierzy korelacji. Przy pomocy skalowania wielowymiarowego oprócz macierzy korelacji, można analizować dowolny rodzaj macierzy podobieństwa lub odmienności. Zmierza do uporządkowania "obiektów" w przestrzeni o danej liczbie wymiarów, tak aby odtworzyć zaobserwowane odległości.
39 Analiza korespondencji Technika analizy tablic dwudzielczych i wielodzielczych, zawierających pewne miary charakteryzujące powiązanie między kolumnami i wierszami.
40 Grupowanie Grupowanie obiektów polega na znajdowaniu skończonego zbioru klas (podzbiorów) w bazie danych. Celem grupowania jest podział zbioru na stosunkowo homogeniczne (jednorodne, zgodne) grupy (klasy) zwane klastrami (skupieniami) różniące się względem siebie.
41 Grupowanie - zastosowania określanie segmentów rynku na podstawie cech klientów, redukcja wymiaru przestrzeni cech na te decydujące o zmienności zjawiska.
42 Drzewa klasyfikacyjne i regresyjne Metody regresji wymagają spełnienia wielu rygorystycznych założeń. Jeżeli wymogi teoretyczne i założenia dotyczące rozkładów oczekiwane przez metody tradycyjne nie są spełnione zalecana jest analiza przy pomocy drzew klasyfikacyjnych i regresyjnych. y zmienna jakościowa drzewa klasyfikacyjne y zmienna ilościowa drzewa regresyjne
43 Klasyfikacja Znajdowanie odwzorowywania danych w zbiór predefiniowanych klas (podzbiorów). Celem klasyfikacji jest budowa modelu (klasyfikatora) który służy do klasyfikowania nowych obiektów w bazie danych lub głębszego zrozumienia istniejącego podziału obiektów na predefiniowane klasy
44 Klasyfikacja Baza danych zawiera obiekty opisane atrybutami (cechami nazywanymi deskryptorami), z których jeden jest atrybutem decyzyjnym Wartości atrybutu decyzyjnego dzielą zbiór krotek na predefiniowane klasy, składające sie z krotek o tej samej wartości atrybutu decyzyjnego
45 Klasyfikacja - zastosowania identyfikacja cech kredytobiorców wiarygodnych i niewiarygodnych, analiza churn.
46 Odkrywanie reguł asocjacji odkrywanie asocjacji pomiędzy atrybutami, analiza podobieństwa - wspólnego występowania, analiza koszyka sklepowego (koszykowa),
47 Reguły asocjacji - zastosowania odkrycie grup objawów wskazujących określoną chorobę budowa modelu wspomagającego decyzję lekarza, odkrycie grup produktów kupowanych podczas jednej transakcji promocje cenowe.
48 Odkrywanie wzorców sekwencji - zastosowania odkrycie grup produktów kupowanych podczas kolejnych transakcji, przewidywanie sprzedaży.
49 Technologie Big Data Przetwarzanie ogromnych zbiorów danych wymaga nie tylko odpowiednich metod, ale również stosownej infrastruktury. Najczęściej aby można było przeprowadzić takie analizy jak te, opisane wyżej potrzebne są potężne komputery oraz wielkie zasoby pamięci i przestrzeni dyskowej.
50 Technologie Big Data W przetwarzania BIG DATA stosuje się obecnie m.in. takie technologie jak: chmura obliczeniowa (cloud computing), platforma Hadoop, bazy danych następnej generacji - NoSQL, narzędzia do wizualizacji
51 Chmura obliczeniowa Chmura obliczeniowa jest to platforma, która zawiera zarówno sprzęt informatyczny (serwerownie) jak i oprogramowanie udostępniane przez Internet. Moc obliczeniowa chmury może być dowolnie zwiększana, odpowiednio do potrzeb użytkownika.
52 Chmura obliczeniowa
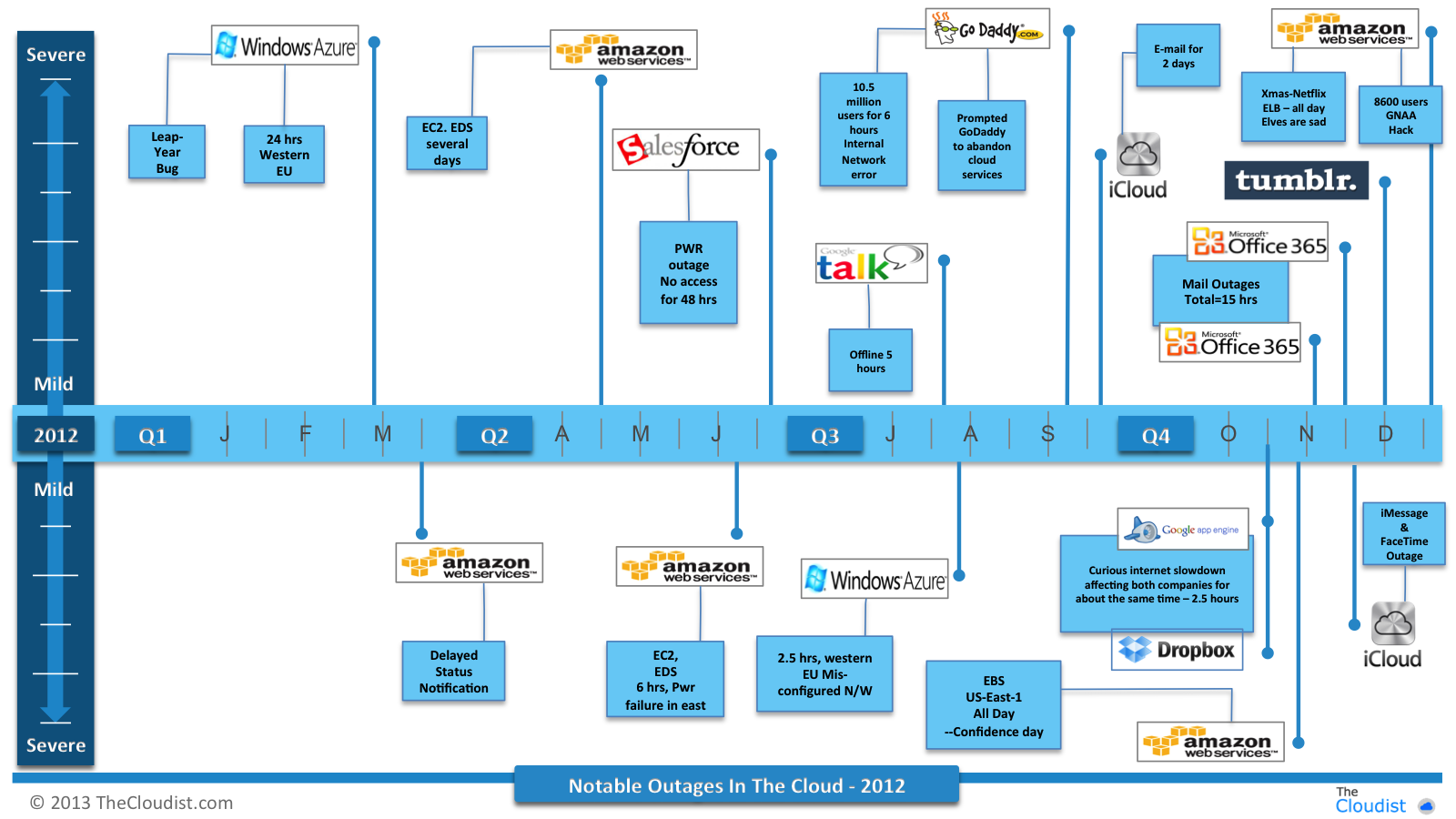
53 Chmura obliczeniowa

54 Platforma Hadoop Platforma Apache Hadoop jest biblioteką programów umożliwiających analizę BIG DATA z dużych rozproszonych zbiorów danych strukturalnych i niestrukturalnych. Oferuje gromadzenie i przetwarzanie danych realizowane przy pomocy nawet do 1000 połączonych serwerów.
55 Platforma Hadoop Elementy składowe Apache Hadoop to: Hadoop Common wspólne narzędzia, które umożliwiają rozwijanie innych modułów Hadoop; Hadoop Distributed File System (HDFS) jego zadaniem jest przechowywanie i zarządzanie plikami na rozproszonych komputerach i zapewnianie wysokiej przepustowości pomiędzy danymi; Hadoop YARN realizuje zarządzanie zasobami i obliczeniami w klastrach oraz tworzy harmonogramy zadań użytkowników;
56 Platforma Hadoop Hadoop MapReduce jest to program pozwalający tworzyć aplikacje do przetwarzania ogromnych ilości danych równolegle na wielu klastrach oraz mechanizm, umożliwiający podział zbioru danych na mniejsze kawałki, które później są analizowane oddzielnie, ale równolegle, a następnie łączący ze sobą otrzymane wyniki.
57 Bazy danych NoSQL Tradycyjne bazy danych w których posługujemy się językiem SQL mają swoje ograniczenia działają na danych ustrukturalizowanych. Przetwarzanie danych różnorodnych wymagało przygotowanie nowych mechanizmów, które właśnie dla odróżnienia od tradycyjnej technologii nazwano NoSQL, co oznacza nie tylko SQL.
58 Bazy danych NoSQL NoSQL skupia się wokół koncepcji rozproszonych baz danych, gdzie dane niestrukturalne mogą być składowane w wielu węzłach przetwarzania. Rozproszona architektura pozwala na skalowanie (powiększanie) poziome bazy danych NoSQL, czyli w sytuacji gwałtownego przyrostu danych można dodać dodatkowe węzły, dzięki czemu przetwarzanie danych nie zostaje spowolnione.
59 DZIĘKUJĘ ZA UWAGĘ
60 Źródła Gołuchowski J. [red.nauk] (2011) Wprowadzenie do inżynierii wiedzy. Podręcznik akademicki, Difin SA, Warszawa. K. Porwit, Cechy gospodarki opartej na wiedzy, [w:] A. Kukliński (red.) (2001) Gospodarka oparta na wiedzy. Wyzwanie dla Polski XXI wieku, Komitet Badań Naukowych, Warszawa. E. Dyson, G. Gilder, G. Keyworth, A. Toffler (1994) Cyberspace and the American Dream: A Magna Carta for the Knowledge Age. In: Future Insight 1.2. The Progress & Freedom Foundation. M. Tabakow, J. Korczak, B. Franczyk, (2014) BIG DATA Definicje, wyzwania i technologie informatyczne, [w:] INFORMATYKA EKONOMICZNA BUSINESS INFORMATICS 1(31),ISSN Controlling-Data-Volume-Velocity-and-Variety.pdf
61
 Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Plan prezentacji 0 Wprowadzenie 0 Zastosowania 0 Przykładowe metody 0 Zagadnienia poboczne 0 Przyszłość 0 Podsumowanie 7 Jak powstaje wiedza? Dane Informacje Wiedza Zrozumienie 8 Przykład Teleskop Hubble
Zagadnienia egzaminacyjne INFORMATYKA. stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1.Tryby komunikacji między procesami w standardzie Message Passing Interface. 2. HTML DOM i XHTML cel i charakterystyka. 3. Asynchroniczna komunikacja serwerem HTTP w technologii
Hadoop i Spark. Mariusz Rafało
 Hadoop i Spark Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl WPROWADZENIE DO EKOSYSTEMU APACHE HADOOP Czym jest Hadoop Platforma służąca przetwarzaniu rozproszonemu dużych zbiorów danych. Jest
Hadoop i Spark Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl WPROWADZENIE DO EKOSYSTEMU APACHE HADOOP Czym jest Hadoop Platforma służąca przetwarzaniu rozproszonemu dużych zbiorów danych. Jest
Transformacja wiedzy w budowie i eksploatacji maszyn
 Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family
 Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów, architektów oraz
Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów, architektów oraz
dr inż. Olga Siedlecka-Lamch 14 listopada 2011 roku Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Eksploracja danych
 - Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
- Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska 14 listopada 2011 roku 1 - - 2 3 4 5 - The purpose of computing is insight, not numbers Richard Hamming Motywacja - Mamy informację,
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Wprowadzenie do Hurtowni Danych
 Wprowadzenie do Hurtowni Danych BIG DATA Definicja Big Data Big Data definiowane jest jako składowanie zbiorów danych o tak dużej złożoności i ilości danych, że jest to niemożliwe przy zastosowaniu podejścia
Wprowadzenie do Hurtowni Danych BIG DATA Definicja Big Data Big Data definiowane jest jako składowanie zbiorów danych o tak dużej złożoności i ilości danych, że jest to niemożliwe przy zastosowaniu podejścia
Szczegółowy opis przedmiotu zamówienia
 ZP/ITS/19/2013 SIWZ Załącznik nr 1.1 do Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych dla studentów
ZP/ITS/19/2013 SIWZ Załącznik nr 1.1 do Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych dla studentów
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Zagadnienia egzaminacyjne INFORMATYKA. Stacjonarne. I-go stopnia. (INT) Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ
 Inżynieria internetowa STOPIEŃ STUDIÓW TYP STUDIÓW SPECJALNOŚĆ") (INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
(INT) Inżynieria internetowa 1. Tryby komunikacji między procesami w standardzie Message Passing Interface 2. HTML DOM i XHTML cel i charakterystyka 3. Asynchroniczna komunikacja serwerem HTTP w technologii
Od Expert Data Scientist do Citizen Data Scientist, czyli jak w praktyce korzystać z zaawansowanej analizy danych
 Od Expert Data Scientist do Citizen Data Scientist, czyli jak w praktyce korzystać z zaawansowanej analizy danych Tomasz Demski StatSoft Polska www.statsoft.pl Analiza danych Zaawansowana analityka, data
Od Expert Data Scientist do Citizen Data Scientist, czyli jak w praktyce korzystać z zaawansowanej analizy danych Tomasz Demski StatSoft Polska www.statsoft.pl Analiza danych Zaawansowana analityka, data
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Zaliczenie: Praca na zajęciach Egzamin Projekt/esej zaliczeniowy Plan zajęć # TEMATYKA ZAJĘĆ
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Zaliczenie: Praca na zajęciach Egzamin Projekt/esej zaliczeniowy Plan zajęć # TEMATYKA ZAJĘĆ
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
w ekonomii, finansach i towaroznawstwie
 w ekonomii, finansach i towaroznawstwie spotykane określenia: zgłębianie danych, eksploracyjna analiza danych, przekopywanie danych, męczenie danych proces wykrywania zależności w zbiorach danych poprzez
w ekonomii, finansach i towaroznawstwie spotykane określenia: zgłębianie danych, eksploracyjna analiza danych, przekopywanie danych, męczenie danych proces wykrywania zależności w zbiorach danych poprzez
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Pojęcie bazy danych. Funkcje i możliwości.
 Pojęcie bazy danych. Funkcje i możliwości. Pojęcie bazy danych Baza danych to: zbiór informacji zapisanych według ściśle określonych reguł, w strukturach odpowiadających założonemu modelowi danych, zbiór
Pojęcie bazy danych. Funkcje i możliwości. Pojęcie bazy danych Baza danych to: zbiór informacji zapisanych według ściśle określonych reguł, w strukturach odpowiadających założonemu modelowi danych, zbiór
Widzenie komputerowe (computer vision)
") Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Widzenie komputerowe (computer vision) dr inż. Marcin Wilczewski 2018/2019 Organizacja zajęć Tematyka wykładu Cele Python jako narzędzie uczenia maszynowego i widzenia komputerowego. Binaryzacja i segmentacja
Wykład I. Wprowadzenie do baz danych
 Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
Wykład I Wprowadzenie do baz danych Trochę historii Pierwsze znane użycie terminu baza danych miało miejsce w listopadzie w 1963 roku. W latach sześcdziesątych XX wieku został opracowany przez Charles
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Alicja Marszałek Różne rodzaje baz danych
 Alicja Marszałek Różne rodzaje baz danych Rodzaje baz danych Bazy danych można podzielić wg struktur organizacji danych, których używają. Można podzielić je na: Bazy proste Bazy złożone Bazy proste Bazy
Alicja Marszałek Różne rodzaje baz danych Rodzaje baz danych Bazy danych można podzielić wg struktur organizacji danych, których używają. Można podzielić je na: Bazy proste Bazy złożone Bazy proste Bazy
Efekt kształcenia. Wiedza
 Efekty dla studiów drugiego stopnia profil ogólnoakademicki na kierunku Informatyka na specjalności Przetwarzanie i analiza danych, na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie oznacza
Efekty dla studiów drugiego stopnia profil ogólnoakademicki na kierunku Informatyka na specjalności Przetwarzanie i analiza danych, na Wydziale Matematyki i Nauk Informacyjnych, gdzie: * Odniesienie oznacza
MODELE LINIOWE. Dr Wioleta Drobik
 MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
MODELE LINIOWE Dr Wioleta Drobik MODELE LINIOWE Jedna z najstarszych i najpopularniejszych metod modelowania Zależność między zbiorem zmiennych objaśniających, a zmienną ilościową nazywaną zmienną objaśnianą
Tematy prac dyplomowych inżynierskich
 inżynierskich Oferujemy możliwość realizowania poniższych tematów w ramach projektu realizowanego ze środków Narodowego Centrum Badań i Rozwoju. Najlepszym umożliwimy realizację pracy dyplomowej w połączeniu
inżynierskich Oferujemy możliwość realizowania poniższych tematów w ramach projektu realizowanego ze środków Narodowego Centrum Badań i Rozwoju. Najlepszym umożliwimy realizację pracy dyplomowej w połączeniu
Szybkość instynktu i rozsądek rozumu$
 Szybkość instynktu i rozsądek rozumu$ zastosowania rozwiązań BigData$ Bartosz Dudziński" Architekt IT! Już nie tylko dokumenty Ilość Szybkość Różnorodność 12 terabajtów milionów Tweet-ów tworzonych codziennie
Szybkość instynktu i rozsądek rozumu$ zastosowania rozwiązań BigData$ Bartosz Dudziński" Architekt IT! Już nie tylko dokumenty Ilość Szybkość Różnorodność 12 terabajtów milionów Tweet-ów tworzonych codziennie
Data Mining Kopalnie Wiedzy
 Data Mining Kopalnie Wiedzy Janusz z Będzina Instytut Informatyki i Nauki o Materiałach Sosnowiec, 30 listopada 2006 Kopalnie złota XIX Wiek. Odkrycie pokładów złota spowodowało napływ poszukiwaczy. Przeczesywali
Data Mining Kopalnie Wiedzy Janusz z Będzina Instytut Informatyki i Nauki o Materiałach Sosnowiec, 30 listopada 2006 Kopalnie złota XIX Wiek. Odkrycie pokładów złota spowodowało napływ poszukiwaczy. Przeczesywali
Analityka danych publicznych dla diagnoz i prognoz dotyczących osób niepełnosprawnych
 XI Konferencja Naukowa Bezpieczeostwo w Internecie. Analityka danych Analityka danych publicznych dla diagnoz i prognoz dotyczących osób niepełnosprawnych Ewa Marzec UKSW Uwagi historyczne Rosnące rozmiary
XI Konferencja Naukowa Bezpieczeostwo w Internecie. Analityka danych Analityka danych publicznych dla diagnoz i prognoz dotyczących osób niepełnosprawnych Ewa Marzec UKSW Uwagi historyczne Rosnące rozmiary
Organizacyjnie. Prowadzący: dr Mariusz Rafało (hasło: BIG)
") Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Automatyzacja Automatyzacja przetwarzania: Apache NiFi Źródło: nifi.apache.org 4 Automatyzacja
Big Data Organizacyjnie Prowadzący: dr Mariusz Rafało mrafalo@sgh.waw.pl http://mariuszrafalo.pl (hasło: BIG) Automatyzacja Automatyzacja przetwarzania: Apache NiFi Źródło: nifi.apache.org 4 Automatyzacja
Bazy Danych. Bazy Danych i SQL Podstawowe informacje o bazach danych. Krzysztof Regulski WIMiIP, KISiM,
 Bazy Danych Bazy Danych i SQL Podstawowe informacje o bazach danych Krzysztof Regulski WIMiIP, KISiM, regulski@metal.agh.edu.pl Oczekiwania? 2 3 Bazy danych Jak przechowywać informacje? Jak opisać rzeczywistość?
Bazy Danych Bazy Danych i SQL Podstawowe informacje o bazach danych Krzysztof Regulski WIMiIP, KISiM, regulski@metal.agh.edu.pl Oczekiwania? 2 3 Bazy danych Jak przechowywać informacje? Jak opisać rzeczywistość?
Indeksy w bazach danych. Motywacje. Techniki indeksowania w eksploracji danych. Plan prezentacji. Dotychczasowe prace badawcze skupiały się na
 Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Statystyka i Analiza Danych
 Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
Warsztaty Statystyka i Analiza Danych Gdańsk, 20-22 lutego 2014 Zastosowania wybranych technik regresyjnych do modelowania współzależności zjawisk Janusz Wątroba StatSoft Polska Centrum Zastosowań Matematyki
STUDIA I MONOGRAFIE NR
 STUDIA I MONOGRAFIE NR 21 WYBRANE ZAGADNIENIA INŻYNIERII WIEDZY Redakcja naukowa: Andrzej Cader Jacek M. Żurada Krzysztof Przybyszewski Łódź 2008 3 SPIS TREŚCI WPROWADZENIE 7 SYSTEMY AGENTOWE W E-LEARNINGU
STUDIA I MONOGRAFIE NR 21 WYBRANE ZAGADNIENIA INŻYNIERII WIEDZY Redakcja naukowa: Andrzej Cader Jacek M. Żurada Krzysztof Przybyszewski Łódź 2008 3 SPIS TREŚCI WPROWADZENIE 7 SYSTEMY AGENTOWE W E-LEARNINGU
LIDERZY DATA SCIENCE CENTRUM TECHNOLOGII ICM CENTRUM TECHNOLOGII ICM ICM UW TO NAJNOWOCZEŚNIEJSZY OŚRODEK DATA SCIENCE W EUROPIE ŚRODKOWEJ.
 ROZUMIEĆ DANE 1 Pozyskiwanie wartościowych informacji ze zbiorów danych to jedna z kluczowych kompetencji warunkujących przewagę konkurencyjną we współczesnej gospodarce. Jednak do efektywnej i wydajnej
ROZUMIEĆ DANE 1 Pozyskiwanie wartościowych informacji ze zbiorów danych to jedna z kluczowych kompetencji warunkujących przewagę konkurencyjną we współczesnej gospodarce. Jednak do efektywnej i wydajnej
Jarosław Żeliński analityk biznesowy, projektant systemów
 Czy chmura może być bezpiecznym backupem? Ryzyka systemowe i prawne. Jarosław Żeliński analityk biznesowy, projektant systemów Agenda Definicja usługi backup i cloud computing Architektura systemu z backupem
Czy chmura może być bezpiecznym backupem? Ryzyka systemowe i prawne. Jarosław Żeliński analityk biznesowy, projektant systemów Agenda Definicja usługi backup i cloud computing Architektura systemu z backupem
Aplikacja inteligentnego zarządzania energią w środowisku domowym jako usługa Internetu Przyszłości
 Aplikacja inteligentnego zarządzania energią w środowisku domowym jako usługa Internetu Przyszłości B. Lewandowski, C. Mazurek, A. Radziuk Konferencja i3, Wrocław, 01 03 grudnia 2010 1 Agenda Internet
Aplikacja inteligentnego zarządzania energią w środowisku domowym jako usługa Internetu Przyszłości B. Lewandowski, C. Mazurek, A. Radziuk Konferencja i3, Wrocław, 01 03 grudnia 2010 1 Agenda Internet
Kierunek:Informatyka- - inż., rok I specjalność: Grafika komputerowa
 :Informatyka- - inż., rok I specjalność: Grafika komputerowa Rok akademicki 018/019 Metody uczenia się i studiowania. 1 Podstawy prawne. 1 Podstawy ekonomii. 1 Matematyka dyskretna. 1 30 Wprowadzenie do
:Informatyka- - inż., rok I specjalność: Grafika komputerowa Rok akademicki 018/019 Metody uczenia się i studiowania. 1 Podstawy prawne. 1 Podstawy ekonomii. 1 Matematyka dyskretna. 1 30 Wprowadzenie do
STRESZCZENIE. rozprawy doktorskiej pt. Zmienne jakościowe w procesie wyceny wartości rynkowej nieruchomości. Ujęcie statystyczne.
 STRESZCZENIE rozprawy doktorskiej pt. Zmienne jakościowe w procesie wyceny wartości rynkowej nieruchomości. Ujęcie statystyczne. Zasadniczym czynnikiem stanowiącym motywację dla podjętych w pracy rozważań
STRESZCZENIE rozprawy doktorskiej pt. Zmienne jakościowe w procesie wyceny wartości rynkowej nieruchomości. Ujęcie statystyczne. Zasadniczym czynnikiem stanowiącym motywację dla podjętych w pracy rozważań
SCENARIUSZ LEKCJI. TEMAT LEKCJI: Zastosowanie średnich w statystyce i matematyce. Podstawowe pojęcia statystyczne. Streszczenie.
 SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
SCENARIUSZ LEKCJI OPRACOWANY W RAMACH PROJEKTU: INFORMATYKA MÓJ SPOSÓB NA POZNANIE I OPISANIE ŚWIATA. PROGRAM NAUCZANIA INFORMATYKI Z ELEMENTAMI PRZEDMIOTÓW MATEMATYCZNO-PRZYRODNICZYCH Autorzy scenariusza:
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
WSTĘP I TAKSONOMIA METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Recenzenci Stefan Mynarski, Waldemar Tarczyński. Redaktor Wydawnictwa Anna Grzybowska. Redaktor techniczny Barbara Łopusiewicz. Korektor Barbara Cibis
 Komitet Redakcyjny Andrzej Matysiak (przewodniczący), Tadeusz Borys, Andrzej Gospodarowicz, Jan Lichtarski, Adam Nowicki, Walenty Ostasiewicz, Zdzisław Pisz, Teresa Znamierowska Recenzenci Stefan Mynarski,
Komitet Redakcyjny Andrzej Matysiak (przewodniczący), Tadeusz Borys, Andrzej Gospodarowicz, Jan Lichtarski, Adam Nowicki, Walenty Ostasiewicz, Zdzisław Pisz, Teresa Znamierowska Recenzenci Stefan Mynarski,
Opis efektów kształcenia dla modułu zajęć
 Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Nazwa modułu: Eksploracja danych Rok akademicki: 2030/2031 Kod: MIS-2-105-MT-s Punkty ECTS: 5 Wydział: Inżynierii Metali i Informatyki Przemysłowej Kierunek: Informatyka Stosowana Specjalność: Modelowanie
Statystyka. Wykład 8. Magdalena Alama-Bućko. 10 kwietnia Magdalena Alama-Bućko Statystyka 10 kwietnia / 31
 Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Statystyka Wykład 8 Magdalena Alama-Bućko 10 kwietnia 2017 Magdalena Alama-Bućko Statystyka 10 kwietnia 2017 1 / 31 Tematyka zajęć: Wprowadzenie do statystyki. Analiza struktury zbiorowości miary położenia
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
KIERUNKOWE EFEKTY KSZTAŁCENIA KIERUNEK STUDIÓW INFORMATYCZNE TECHNIKI ZARZĄDZANIA
 KIERUNKOWE EFEKTY KSZTAŁCENIA KIERUNEK STUDIÓW INFORMATYCZNE TECHNIKI ZARZĄDZANIA Nazwa kierunku studiów: Informatyczne Techniki Zarządzania Ścieżka kształcenia: IT Project Manager, Administrator Bezpieczeństwa
KIERUNKOWE EFEKTY KSZTAŁCENIA KIERUNEK STUDIÓW INFORMATYCZNE TECHNIKI ZARZĄDZANIA Nazwa kierunku studiów: Informatyczne Techniki Zarządzania Ścieżka kształcenia: IT Project Manager, Administrator Bezpieczeństwa
Systemy baz danych w zarządzaniu przedsiębiorstwem. W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi
 Systemy baz danych w zarządzaniu przedsiębiorstwem W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi Proces zarządzania danymi Zarządzanie danymi obejmuje czynności: gromadzenie
Systemy baz danych w zarządzaniu przedsiębiorstwem W poszukiwaniu rozwiązania problemu, najbardziej pomocna jest znajomość odpowiedzi Proces zarządzania danymi Zarządzanie danymi obejmuje czynności: gromadzenie
Rok akademicki: 2030/2031 Kod: ZZP MK-n Punkty ECTS: 3. Poziom studiów: Studia II stopnia Forma i tryb studiów: Niestacjonarne
 Nazwa modułu: Komputerowe wspomaganie decyzji Rok akademicki: 2030/2031 Kod: ZZP-2-403-MK-n Punkty ECTS: 3 Wydział: Zarządzania Kierunek: Zarządzanie Specjalność: Marketing Poziom studiów: Studia II stopnia
Nazwa modułu: Komputerowe wspomaganie decyzji Rok akademicki: 2030/2031 Kod: ZZP-2-403-MK-n Punkty ECTS: 3 Wydział: Zarządzania Kierunek: Zarządzanie Specjalność: Marketing Poziom studiów: Studia II stopnia
Analiza danych i data mining.
 Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
ZAGADNIENIA DO EGZAMINU DYPLOMOWEGO NA STUDIACH INŻYNIERSKICH. Matematyka dyskretna, algorytmy i struktury danych, sztuczna inteligencja
 Kierunek Informatyka Rok akademicki 2016/2017 Wydział Matematyczno-Przyrodniczy Uniwersytet Rzeszowski ZAGADNIENIA DO EGZAMINU DYPLOMOWEGO NA STUDIACH INŻYNIERSKICH Technika cyfrowa i architektura komputerów
Kierunek Informatyka Rok akademicki 2016/2017 Wydział Matematyczno-Przyrodniczy Uniwersytet Rzeszowski ZAGADNIENIA DO EGZAMINU DYPLOMOWEGO NA STUDIACH INŻYNIERSKICH Technika cyfrowa i architektura komputerów
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Skalowanie wielowymiarowe idea
 Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Skalowanie wielowymiarowe idea Jedną z wad metody PCA jest możliwość używania jedynie zmiennych ilościowych, kolejnym konieczność posiadania pełnych danych z doświadczenia(nie da się użyć PCA jeśli mamy
Nowe narzędzia zarządzania jakością
 Nowe narzędzia zarządzania jakością Agnieszka Michalak 106947 Piotr Michalak 106928 Filip Najdek 106946 Co to jest? Nowe narzędzia jakości - grupa siedmiu nowych narzędzi zarządzania jakością, które mają
Nowe narzędzia zarządzania jakością Agnieszka Michalak 106947 Piotr Michalak 106928 Filip Najdek 106946 Co to jest? Nowe narzędzia jakości - grupa siedmiu nowych narzędzi zarządzania jakością, które mają
W1. Wprowadzenie. Statystyka opisowa
 W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
W1. Wprowadzenie. Statystyka opisowa dr hab. Jerzy Nakielski Zakład Biofizyki i Morfogenezy Roślin Plan wykładu: 1. O co chodzi w statystyce 2. Etapy badania statystycznego 3. Zmienna losowa, rozkład
Data Mining Wykład 1. Wprowadzenie do Eksploracji Danych. Prowadzący. Dr inż. Jacek Lewandowski
 Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Rozdział 1. Zarządzanie wiedzą we współczesnych organizacjach gospodarczych Zarządzanie wiedzą w Polsce i na świecie w świetle ostatnich lat
 Zarządzanie wiedzą we współczesnym przedsiębiorstwie Autor: Marcin Kłak Wstęp Rozdział 1. Zarządzanie wiedzą we współczesnych organizacjach gospodarczych 1.1. Rola i znaczenie wiedzy 1.1.1. Pojęcia i definicje
Zarządzanie wiedzą we współczesnym przedsiębiorstwie Autor: Marcin Kłak Wstęp Rozdział 1. Zarządzanie wiedzą we współczesnych organizacjach gospodarczych 1.1. Rola i znaczenie wiedzy 1.1.1. Pojęcia i definicje
Wstęp... 9. Podstawowe oznaczenia stosowane w książce... 13
 Spis treści Wstęp... 9 Podstawowe oznaczenia stosowane w książce... 13 1. PODEJŚCIE SYMBOLICZNE W BADANIACH EKONOMICZ- NYCH... 15 1.1. Uwagi dotyczące przyjętych w rozdziale konwencji nomenklaturowych.
Spis treści Wstęp... 9 Podstawowe oznaczenia stosowane w książce... 13 1. PODEJŚCIE SYMBOLICZNE W BADANIACH EKONOMICZ- NYCH... 15 1.1. Uwagi dotyczące przyjętych w rozdziale konwencji nomenklaturowych.
Jak stworzyć i rozwijać sieć agroturystyczną. Koncepcje, finanse, marketing
 http://www.varbak.com/fotografia/olbrzym-zdj%c4%99%c4%87-sie%c4%87-paj%c4%85ka; 15.10.2012 Jak stworzyć i rozwijać sieć agroturystyczną. Koncepcje, finanse, marketing dr Anna Jęczmyk Uniwersytet Przyrodniczy
http://www.varbak.com/fotografia/olbrzym-zdj%c4%99%c4%87-sie%c4%87-paj%c4%85ka; 15.10.2012 Jak stworzyć i rozwijać sieć agroturystyczną. Koncepcje, finanse, marketing dr Anna Jęczmyk Uniwersytet Przyrodniczy
PRZEWODNIK PO PRZEDMIOCIE
 Nazwa przedmiotu: SYSTEMY INFORMATYCZNE WSPOMAGAJĄCE DIAGNOSTYKĘ MEDYCZNĄ Kierunek: Inżynieria Biomedyczna Rodzaj przedmiotu: obowiązkowy moduł specjalności informatyka medyczna Rodzaj zajęć: wykład, projekt
Nazwa przedmiotu: SYSTEMY INFORMATYCZNE WSPOMAGAJĄCE DIAGNOSTYKĘ MEDYCZNĄ Kierunek: Inżynieria Biomedyczna Rodzaj przedmiotu: obowiązkowy moduł specjalności informatyka medyczna Rodzaj zajęć: wykład, projekt
Systemy zarządzania wiedzą w strategiach firm. Prof. dr hab. Irena Hejduk Szkoła Głowna Handlowa w Warszawie
 Systemy zarządzania wiedzą w strategiach firm Prof. dr hab. Irena Hejduk Szkoła Głowna Handlowa w Warszawie Wprowadzenie istota zarządzania wiedzą Wiedza i informacja, ich jakość i aktualność stają się
Systemy zarządzania wiedzą w strategiach firm Prof. dr hab. Irena Hejduk Szkoła Głowna Handlowa w Warszawie Wprowadzenie istota zarządzania wiedzą Wiedza i informacja, ich jakość i aktualność stają się
SPIS TREŚCI. Do Czytelnika... 7
 SPIS TREŚCI Do Czytelnika.................................................. 7 Rozdział I. Wprowadzenie do analizy statystycznej.............. 11 1.1. Informacje ogólne..........................................
SPIS TREŚCI Do Czytelnika.................................................. 7 Rozdział I. Wprowadzenie do analizy statystycznej.............. 11 1.1. Informacje ogólne..........................................
Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne. Wykład Ćwiczenia
 Wydział: Informatyki, Elektroniki i Telekomunikacji Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne Rocznik: 217/218 Język wykładowy: Polski Semestr 1 IIN-1-13-s
Wydział: Informatyki, Elektroniki i Telekomunikacji Kierunek: Informatyka Poziom studiów: Studia I stopnia Forma i tryb studiów: Stacjonarne Rocznik: 217/218 Język wykładowy: Polski Semestr 1 IIN-1-13-s
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej
 Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Elementy statystyki opisowej, podstawowe pojęcia statystyki matematycznej Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Księgowość w chmurze
 Księgowość w chmurze Chwilowa moda czy przyszłość finansów? KRZYSZTOF MADEJCZYK EKSPERT OŚWIATOWY Co to jest chmura obliczeniowa? Co to jest chmura obliczeniowa? Co to jest chmura obliczeniowa? Co to jest
Księgowość w chmurze Chwilowa moda czy przyszłość finansów? KRZYSZTOF MADEJCZYK EKSPERT OŚWIATOWY Co to jest chmura obliczeniowa? Co to jest chmura obliczeniowa? Co to jest chmura obliczeniowa? Co to jest
Podstawowe pojęcia dotyczące relacyjnych baz danych. mgr inż. Krzysztof Szałajko
 Podstawowe pojęcia dotyczące relacyjnych baz danych mgr inż. Krzysztof Szałajko Czym jest baza danych? Co rozumiemy przez dane? Czym jest system zarządzania bazą danych? 2 / 25 Baza danych Baza danych
Podstawowe pojęcia dotyczące relacyjnych baz danych mgr inż. Krzysztof Szałajko Czym jest baza danych? Co rozumiemy przez dane? Czym jest system zarządzania bazą danych? 2 / 25 Baza danych Baza danych
Laboratorium demonstrator bazowych technologii Przemysłu 4.0 przykład projektu utworzenia laboratorium przez KSSE i Politechnikę Śląską
 Laboratorium demonstrator bazowych technologii Przemysłu 4.0 przykład projektu utworzenia laboratorium przez KSSE i Politechnikę Śląską (wynik prac grupy roboczej ds. kształcenia, kompetencji i zasobów
Laboratorium demonstrator bazowych technologii Przemysłu 4.0 przykład projektu utworzenia laboratorium przez KSSE i Politechnikę Śląską (wynik prac grupy roboczej ds. kształcenia, kompetencji i zasobów
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
data mining machine learning data science
 data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
Ontologie, czyli o inteligentnych danych
 1 Ontologie, czyli o inteligentnych danych Bożena Deka Andrzej Tolarczyk PLAN 2 1. Korzenie filozoficzne 2. Ontologia w informatyce Ontologie a bazy danych Sieć Semantyczna Inteligentne dane 3. Zastosowania
1 Ontologie, czyli o inteligentnych danych Bożena Deka Andrzej Tolarczyk PLAN 2 1. Korzenie filozoficzne 2. Ontologia w informatyce Ontologie a bazy danych Sieć Semantyczna Inteligentne dane 3. Zastosowania
Kierunek:Informatyka- - inż., rok I specjalność: Grafika komputerowa i multimedia
 :Informatyka- - inż., rok I specjalność: Grafika komputerowa i multimedia Podstawy prawne. 1 15 1 Podstawy ekonomii. 1 15 15 2 Metody uczenia się i studiowania. 1 15 1 Środowisko programisty. 1 30 3 Komputerowy
:Informatyka- - inż., rok I specjalność: Grafika komputerowa i multimedia Podstawy prawne. 1 15 1 Podstawy ekonomii. 1 15 15 2 Metody uczenia się i studiowania. 1 15 1 Środowisko programisty. 1 30 3 Komputerowy
Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych
 Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Temat: Data mininig i wielowymiarowa analiza danych zgromadzonych w systemach medycznych na potrzeby badań naukowych Autorzy: Tomasz Małyszko, Edyta Łukasik 1. Definicja eksploracji danych Eksploracja
Kodowanie produktów - cz. 1
 Kodowanie produktów - cz. 1 25.07.2005 r. Wstęp Do identyfikacji wyrobów od dawna używa się różnego rodzaju kodów i klasyfikacji. Obecnie stosuje się m.in. natowską kodyfikację wyrobów, kodowanie wyrobów
Kodowanie produktów - cz. 1 25.07.2005 r. Wstęp Do identyfikacji wyrobów od dawna używa się różnego rodzaju kodów i klasyfikacji. Obecnie stosuje się m.in. natowską kodyfikację wyrobów, kodowanie wyrobów
Przetwarzanie i zabezpieczenie danych w zewnętrznym DATA CENTER
 Przetwarzanie i zabezpieczenie danych w zewnętrznym DATA CENTER Gdańsk, 27-28 września 2012 r. Krzysztof Pytliński Zakład Teleinformatyki Kontekst Data Center jako usługa zewnętrzna, zaspokajająca potrzeby
Przetwarzanie i zabezpieczenie danych w zewnętrznym DATA CENTER Gdańsk, 27-28 września 2012 r. Krzysztof Pytliński Zakład Teleinformatyki Kontekst Data Center jako usługa zewnętrzna, zaspokajająca potrzeby
Jakub Kisielewski. www.administracja.comarch.pl
 Nowatorski punkt widzenia możliwości analitycznosprawozdawczych w ochronie zdrowia na przykładzie systemu Elektronicznej Platformy Gromadzenia, Analizy i Udostępniania zasobów cyfrowych o Zdarzeniach Medycznych
Nowatorski punkt widzenia możliwości analitycznosprawozdawczych w ochronie zdrowia na przykładzie systemu Elektronicznej Platformy Gromadzenia, Analizy i Udostępniania zasobów cyfrowych o Zdarzeniach Medycznych
Metodologia badań psychologicznych
 Metodologia badań psychologicznych Lucyna Golińska SPOŁECZNA AKADEMIA NAUK Psychologia jako nauka empiryczna Wprowadzenie pojęć Wykład 5 Cele badań naukowych 1. Opis- (funkcja deskryptywna) procedura definiowania
Metodologia badań psychologicznych Lucyna Golińska SPOŁECZNA AKADEMIA NAUK Psychologia jako nauka empiryczna Wprowadzenie pojęć Wykład 5 Cele badań naukowych 1. Opis- (funkcja deskryptywna) procedura definiowania
Business Intelligence jako narzędzie do walki z praniem brudnych pieniędzy
 Business www.comarch.pl Intelligence jako narzędzie do walki z praniem brudnych pieniędzy Business Intelligence jako narzędzie do walki z praniem brudnych pieniędzy Tomasz Matysik Kołobrzeg, 19.11.2009
Business www.comarch.pl Intelligence jako narzędzie do walki z praniem brudnych pieniędzy Business Intelligence jako narzędzie do walki z praniem brudnych pieniędzy Tomasz Matysik Kołobrzeg, 19.11.2009
Security Master Class
 Security Master Class Platforma kompleksowej analizy zdarzeń Linux Polska SIEM Radosław Żak-Brodalko Senior Solutions Architect Linux Polska sp. z o.o. Podstawowe problemy Jak pokryć lukę między technicznym
Security Master Class Platforma kompleksowej analizy zdarzeń Linux Polska SIEM Radosław Żak-Brodalko Senior Solutions Architect Linux Polska sp. z o.o. Podstawowe problemy Jak pokryć lukę między technicznym
PODSTAWY BAZ DANYCH. 19. Perspektywy baz danych. 2009/2010 Notatki do wykładu "Podstawy baz danych"
 PODSTAWY BAZ DANYCH 19. Perspektywy baz danych 1 Perspektywy baz danych Temporalna baza danych Temporalna baza danych - baza danych posiadająca informację o czasie wprowadzenia lub czasie ważności zawartych
PODSTAWY BAZ DANYCH 19. Perspektywy baz danych 1 Perspektywy baz danych Temporalna baza danych Temporalna baza danych - baza danych posiadająca informację o czasie wprowadzenia lub czasie ważności zawartych
Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop Spis treści
 Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop. 2017 Spis treści O autorach 9 0 recenzencie 10 Wprowadzenie 11 Rozdział 1. Pierwsze kroki 15 Wprowadzenie do nauki o danych
Python : podstawy nauki o danych / Alberto Boschetti, Luca Massaron. Gliwice, cop. 2017 Spis treści O autorach 9 0 recenzencie 10 Wprowadzenie 11 Rozdział 1. Pierwsze kroki 15 Wprowadzenie do nauki o danych
Technologia informacyjna (IT - Information Technology) dziedzina wiedzy obejmująca:
 dziedzina wiedzy obejmująca:") 1.1. Podstawowe pojęcia Technologia informacyjna (IT - Information Technology) dziedzina wiedzy obejmująca: informatykę (włącznie ze sprzętem komputerowym oraz oprogramowaniem używanym do tworzenia, przesyłania,
1.1. Podstawowe pojęcia Technologia informacyjna (IT - Information Technology) dziedzina wiedzy obejmująca: informatykę (włącznie ze sprzętem komputerowym oraz oprogramowaniem używanym do tworzenia, przesyłania,
System informatyczny zdalnego egzaminowania
 System informatyczny zdalnego egzaminowania - strategia, logika systemu, architektura, ewaluacja (platforma informatyczna e-matura) redakcja Sławomir Wiak Konrad Szumigaj Redakcja: prof. dr hab. inż. Sławomir
System informatyczny zdalnego egzaminowania - strategia, logika systemu, architektura, ewaluacja (platforma informatyczna e-matura) redakcja Sławomir Wiak Konrad Szumigaj Redakcja: prof. dr hab. inż. Sławomir
Rozpocznij swój pierwszy projekt IoT i AR z Transition Technologies PSC
 Rozpocznij swój pierwszy projekt IoT i AR z Transition Technologies PSC _www.ttpsc.pl _iot@ttpsc.pl Transition Technologies PSC Sp. z o.o. Łódź, Piotrkowska 276, 90-361 tel.: +48 42 664 97 20 fax: +48
Rozpocznij swój pierwszy projekt IoT i AR z Transition Technologies PSC _www.ttpsc.pl _iot@ttpsc.pl Transition Technologies PSC Sp. z o.o. Łódź, Piotrkowska 276, 90-361 tel.: +48 42 664 97 20 fax: +48
Wielowymiarowa analiza regionalnego zróżnicowania rolnictwa w Polsce
 Wielowymiarowa analiza regionalnego zróżnicowania rolnictwa w Polsce Mgr inż. Agata Binderman Dzienne Studia Doktoranckie przy Wydziale Ekonomiczno-Rolniczym Katedra Ekonometrii i Informatyki SGGW Opiekun
Wielowymiarowa analiza regionalnego zróżnicowania rolnictwa w Polsce Mgr inż. Agata Binderman Dzienne Studia Doktoranckie przy Wydziale Ekonomiczno-Rolniczym Katedra Ekonometrii i Informatyki SGGW Opiekun
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1.
 Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Teraz bajty. Informatyka dla szkół ponadpodstawowych. Zakres rozszerzony. Część 1. Grażyna Koba MIGRA 2019 Spis treści (propozycja na 2*32 = 64 godziny lekcyjne) Moduł A. Wokół komputera i sieci komputerowych
Model logiczny SZBD. Model fizyczny. Systemy klientserwer. Systemy rozproszone BD. No SQL
 Podstawy baz danych: Rysunek 1. Tradycyjne systemy danych 1- Obsługa wejścia 2- Przechowywanie danych 3- Funkcje użytkowe 4- Obsługa wyjścia Ewolucja baz danych: Fragment świata rzeczywistego System przetwarzania
Podstawy baz danych: Rysunek 1. Tradycyjne systemy danych 1- Obsługa wejścia 2- Przechowywanie danych 3- Funkcje użytkowe 4- Obsługa wyjścia Ewolucja baz danych: Fragment świata rzeczywistego System przetwarzania
Współczesna problematyka klasyfikacji Informatyki
 Współczesna problematyka klasyfikacji Informatyki Nazwa pojawiła się na przełomie lat 50-60-tych i przyjęła się na dobre w Europie Jedna z definicji (z Wikipedii): Informatyka dziedzina nauki i techniki
Współczesna problematyka klasyfikacji Informatyki Nazwa pojawiła się na przełomie lat 50-60-tych i przyjęła się na dobre w Europie Jedna z definicji (z Wikipedii): Informatyka dziedzina nauki i techniki
Baza danych. Baza danych to:
 Baza danych Baza danych to: zbiór danych o określonej strukturze, zapisany na zewnętrznym nośniku (najczęściej dysku twardym komputera), mogący zaspokoić potrzeby wielu użytkowników korzystających z niego
Baza danych Baza danych to: zbiór danych o określonej strukturze, zapisany na zewnętrznym nośniku (najczęściej dysku twardym komputera), mogący zaspokoić potrzeby wielu użytkowników korzystających z niego
Analiza i wizualizacja danych Data analysis and visualization
 KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/2013
KARTA MODUŁU / KARTA PRZEDMIOTU Załącznik nr 7 do Zarządzenia Rektora nr 10/12 z dnia 21 lutego 2012r. Kod modułu Nazwa modułu Nazwa modułu w języku angielskim Obowiązuje od roku akademickiego 2012/2013
Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family
 Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Partner merytoryczny Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów,
Kod szkolenia: Tytuł szkolenia: HADOOP Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family Dni: 5 Partner merytoryczny Opis: Adresaci szkolenia: Szkolenie jest adresowane do programistów,
Co to jest Business Intelligence?
 Cykl: Cykl: Czwartki z Business Intelligence Sesja: Co Co to jest Business Intelligence? Bartłomiej Graczyk 2010-05-06 1 Prelegenci cyklu... mariusz@ssas.pl lukasz@ssas.pl grzegorz@ssas.pl bartek@ssas.pl
Cykl: Cykl: Czwartki z Business Intelligence Sesja: Co Co to jest Business Intelligence? Bartłomiej Graczyk 2010-05-06 1 Prelegenci cyklu... mariusz@ssas.pl lukasz@ssas.pl grzegorz@ssas.pl bartek@ssas.pl
Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem. dr Jakub Boratyński. pok. A38
 Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem zajęcia 1 dr Jakub Boratyński pok. A38 Program zajęć Bazy danych jako podstawowy element systemów informatycznych wykorzystywanych
Podstawowe pakiety komputerowe wykorzystywane w zarządzaniu przedsiębiorstwem zajęcia 1 dr Jakub Boratyński pok. A38 Program zajęć Bazy danych jako podstawowy element systemów informatycznych wykorzystywanych
Marcin Kłak Zarządzanie wiedzą we współczesnym przedsiębiorstwie
 Marcin Kłak Zarządzanie wiedzą we współczesnym przedsiębiorstwie Wydawnictwo Wyższej Szkoły Ekonomii i Prawa im. prof. Edwarda Lipińskiego w Kielcach Kielce czerwiec 2010 1 Spis treści Wstęp 7 Rozdział
Marcin Kłak Zarządzanie wiedzą we współczesnym przedsiębiorstwie Wydawnictwo Wyższej Szkoły Ekonomii i Prawa im. prof. Edwarda Lipińskiego w Kielcach Kielce czerwiec 2010 1 Spis treści Wstęp 7 Rozdział
Baza danych. Modele danych
 Rola baz danych Systemy informatyczne stosowane w obsłudze działalności gospodarczej pełnią funkcję polegającą na gromadzeniu i przetwarzaniu danych. Typowe operacje wykonywane na danych w systemach ewidencyjno-sprawozdawczych
Rola baz danych Systemy informatyczne stosowane w obsłudze działalności gospodarczej pełnią funkcję polegającą na gromadzeniu i przetwarzaniu danych. Typowe operacje wykonywane na danych w systemach ewidencyjno-sprawozdawczych
Modelowanie glikemii w procesie insulinoterapii
 Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą