Eksploracja danych Jacek Rumiński
|
|
|
- Judyta Szczepańska
- 8 lat temu
- Przeglądów:
Transkrypt
1 Eksploracja danych Jacek Rumiński slajd 1 Kontakt: Katedra Inżynierii Biomedycznej, pk. 106, tel.: , fax: , jwr@eti.pg.gda.pl

2 Źródła, Internet, SQL/MM i inne standardy (dodatkowy zestaw slajdów) slajd 2

3 Problem potop danych Ilość generowanych i gromadzonych danych rośnie lawinowo (rozwój zarówno narzędzi wspomagających wytworzenie danych cyfrowych jak i technologii składowania danych) Tworzone zasoby (np. serwisy WWW) dostarczają licznych danych problemem jest jednak odkrycie wiedzy w nich ukrytych Możliwe rozwiązania: - hurtownie danych i OLAP, - odkrywanie wiedzy (reguł, klas, wzorców, regularności, ograniczeń, itp.) KDD Knowledge Discovery in Databases slajd 3

4 Eksploracja danych (Data mining) Eksploracja danych : Uzyskanie nietrywialnych, ukrytych, poprzednio nieznanych a potencjalnie użytecznych informacji lub reguł na podstawie dużych kolekcji danych. Eksploracją danych nie jest: Pozyskiwanie danych na podstawie przygotowanych (wzorców a priori) wyrażeń SQL, Pozyskiwanie danych z wykorzystaniem systemów eksperckich. Spotykane alternatywne lub zbliżone określenia dla eksploracji danych: data mining, Knowledge discovery(mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting, business intelligence, etc. slajd 4

5 Zastosowania eksploracji danych Eksploracja danych stosowania jest głównie jako metodologia inteligentnego wspomagania podejmowania decyzji oraz formułowania wiedzy np.: klasyfikacja klientów firmy, klasyfikacja użytkowników serwisów WWW, formułowanie tez wiedzy ogólnej dotyczących np. istnienia nowych ciał niebieskich lub okoliczności występowania danej zmiany chorobowej, prognozowanie popytu i podaży, identyfikacja potrzeb klientów / użytkowników, wykrywanie zagrożeń i defraudacji (np. środków budżetowych), itd. slajd 5

6 Proces odkrywania wiedzy - diagram Eksploracja danych Podzbiór danych realizowanego zadania Reguły Przetwarzanie reguł Hurtownia Selekcja danych Czyszczenie danych Integracja danych slajd 6 Bazy danych

7 Insightful Miner slajd 7

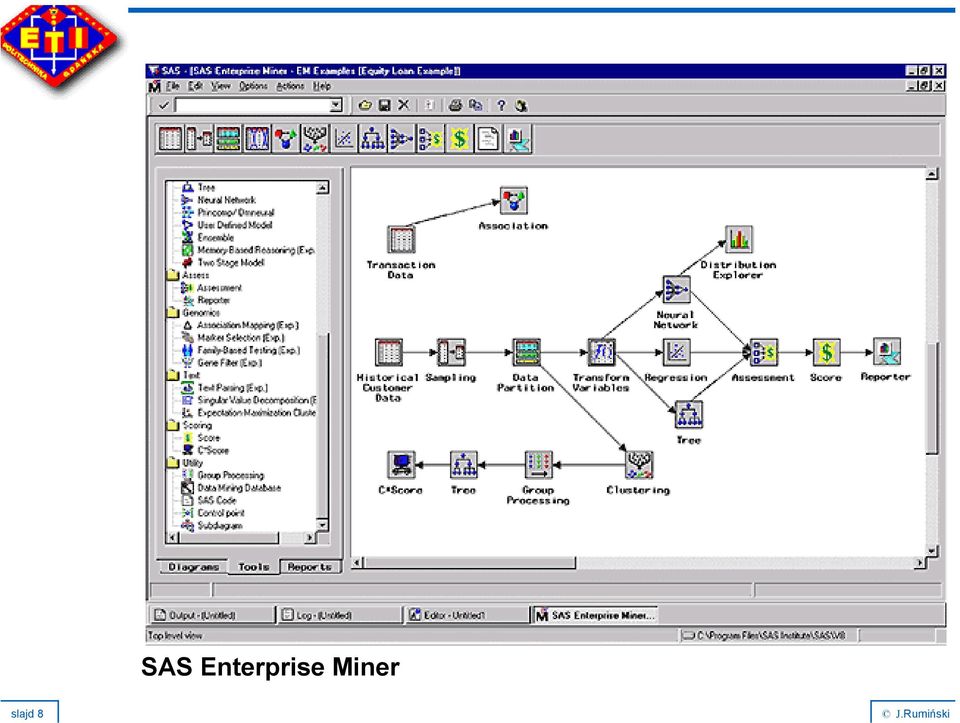
8 SAS Enterprise Miner slajd 8
9 Proces odkrywania wiedzy - kroki Definicja celów oraz zakresu analiz, Selekcja danych z dostępnych źródeł (bazy dane, hurtownie) dla potrzeb utworzenia podzbioru danych związanego z określonym celem analiz, Czyszczenie danych i przetwarzanie wstępne (często niezwykle złożone), Redukcja i transformacja danych (pozostawienie tego co istotne we właściwej formie), Wybór i zastosowanie określonych metod i algorytmów eksploracji danych (np. klasyfikacji danych, określenie trendów, itd..) Przetwarzanie (np. usuwanie klas nieistotnych) i prezentacja odkrytych reguł, wzorców i informacji, Formułowanie i zastosowanie wiedzy (zdań szczegółowych ogólnych). slajd 9
 Przetwarzanie (np.")
10 EKSPLORACJA DANYCH - PLAN PRZETWARZANIE WSTEPNE - CZYSZCZENIE DANYCH, REDUKCJE, TRANSFORMACJE METODY (TECHNIKI EKSPLORACJI WIEDZY): A. Charakterystyki B. Reguły asocjacyjne C. Klasyfikacja D. Segmentacja E. Inne ZASTOSOWANIA slajd 10

11 Proces odkrywania wiedzy a BI Buisness Intelligence Wskaźnik zastosowania technologii w podejmowaniu decyzji Podjęcie decyzji Użytkownik końcowy Prezentacja danych Techniki wizualizacji Eksploracja danych Analityk (rynku, bankowy...) Analityk danych Analiza danych slajd 11 Hurtownie OLAP, MDA Źródła danych Dokumentacja papierowa, pliki, serwisy, OLTP, inne DBA
 Analityk danych Analiza danych slajd 11 Hurtownie OLAP, MDA Źródła danych Dokumentacja")
12 Eksploracja danych metodologia Charakterystki i uogólnienia Generalizacja, podsumowania, charakterystyka różnicowa, np. zdrowe i chore obszary tkanki, Określenie asocjacji (correlation and causality) Wielowymiarowe a jednowymiarowe asocjacje, wiek(x, ) ^ dochód(x, 2K..4K ) ^ kupuje(x, PC ) [support = 2%, confidence = 60%] zawiera(t, PC ) ^ zawiera(x, oprogramowanie ) [1%, 75%] slajd 12
 ^ dochód(x, 2K.")
13 slajd 13 Eksploracja danych metodologia Klasyfikacja i predykcja Znane wzorce/etykiety klas, Poszukiwanie są funkcje (modele, klasyfikatory) opisujące i rozdzielające poszczególne klasy dla potrzeb przyszłych analiz i predykcji (przewidzenia nieznanych lub brakujących wartości), Definiowane są przestrzenie cech, mierzone (wybierane) są wartości opisujące te cechy deskryptory, Przykłady: klasyfikacja studentów na podstawie ich ocen, klasyfikacja klientów na podstawie ich dochodów i rozchodów, Prezentacje: Reguły klasyfikacji, drzewa decyzyjne, sieci neuronowe, itd. Segmentacja/wydzielanie klastrów Nieznane wzorce/etykiety klas grupowanie danych w nowe klasy, identyfikacja klas, Analiza statystyczna danych minimalizacja wariancji rozkładu danych w obrębie klastra (klasy), Określenie minimalnej odległości (maksymalnego podobieństwa) zbioru deskryptorów danego elementu (obiektu) do średniego zbioru deskryptorów klastra.

14 Eksploracja danych metodologia Analiza ekstremów (odstępstw) Ektremum (odstępstwo, wyjątek): obiekt danych niezgodny z ogólną regułą danego zestawu, Wykorzystywana w detekcji błędów, defraudacji, niewłaściwych metod, itd. Analiza trendów Regresja, Identyfikacja parametrów modeli, Analiza okresowości danych, Analiza podobieństw danych, Inne slajd 14

15 Eksploracja danych przetwarzanie reguł Eksploracja danych może wygenerować tysiące reguł/wzorców, spośród których, tylko nieliczne są ważne dla danego celu i zakresu analiz. Dana reguła/wzorzec jest interesująca/ważna jeśli jest łatwo zrozumiała przez człowieka, powtarzalna dla nowych/testowych danych, jest potencjalnie użyteczna i nowa, a zarazem potwierdza hipotezy postawione przez użytkonika przed eksploracją danych - OPTYMALIZACJA Miary oceny reguł: Obiektywne: konstruowane na podstawie struktury i statystyki reguł, np. support, confidence, i inne. Subiektywne: konstruowane na podstawie oceny użytkownika (ekspert), np. unexpectedness, novelty, actionability, inne. slajd 15

16 Wstępne przetwarzanie danych - potrzeby Gromadzone dane są często - niekompletne: brakujące wartości atrybutów, brak istotnych dla analiz atrybutów, brak danych szczegółowych, -posiadają błędy lub wartości nieoczekiwane (odstępstwa), - niejednorodne: stosowanie różnych reguł dla składowania tych samych atrybutów, stosowanie różnych miar (jednostek), itd. Cel eksploracji danych wiedza zależy od jakości danych źródłowych. Złe dane - Nieprawdziwa wiedza błędne decyzje!!! slajd 16

17 Wstępne przetwarzanie danych - zadania Czyszczenie danych (Data cleaning) Uzupełnienie wartości brakujących, usuwanie szumu i błędów danych, identyfikacja i eliminacja odstępstw, usuwanie niejednorodności Integracja danych (Data integration) Integracja wielu baz danych, tabel, kolekcji, plików, kostek danych, itd. Transformacja danych (Data transformation) Normalizacja danych, agregacja Redukcja danych (Data reduction) Usuwanie redundancji, eliminacja danych nie wpływających na uzyskanie poprawnego wyniku Dyskretyzacja/kwantyzacja danych (Data discretization) Szczególna postać redukcji danych numerycznych slajd 17
 Szczególna postać redukcji danych numerycznych slajd 17")
18 Wstępne przetwarzanie danych - zadania slajd 18

19 Ignorowanie krotek, obiektów, wierszy,.., z atrybutami/polami o brakujących wartościach; operacja trudna gdy liczba takich elementów jest duża utrata danych; Ręczne uzupełnienie danych nudne, pracochłonne, często wręcz nierealne; Automatyczne uzupełnienie atrybutów/pól pustych wartościami domyślnymi, DC -> > Brakujące dane Automatyczne uzupełnienie atrybutów/pól pustych wartościami średnimi dla danego sąsiedztwa, klasy, itp.; Automatyczne uzupełnienie atrybutów/pól pustych wartościami najbardziej prawdopodobnymi zastosowanie reguły Bayesa lub drzew decyzyjnych. slajd 19

20 DC -> > Szumy, błędy i ekstrema Metody progowania/grupowania danych: 1. Sortowanie danych, podział na równe liczebnie grupy, 2. Wygładzenie wartości poprzez uśrednienie wartości w obrębie grupy, wyznaczenie mediany grupy, wygładzenie przez ekstrema grupy, itp. Metody segmentacji / wydzielania klastrów Detekcja i usunięcie ekstremów (odstępstw). Metody półautomatyczne Automatyczna detekcja błędu/ektremum; ręczna korekta wartości. Metody wyznaczania trendu - regresja Wygładzenie poprzez zastosowanie wyznaczonej funkcji opisującej rozkład wartości. slajd 20

21 DC -> > Szumy, błędy i ekstrema -> > wygładzanie 1. Posortowanie danych (np. cena towaru w PLN) 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34 Podział na równe grupy: - G1: 4, 8, 9, 15 - G2: 21, 21, 24, 25 - G3: 26, 28, 29, Wygładzenie przez średnią: - G1: 9, 9, 9, 9 - G2: 23, 23, 23, 23 - G3: 29, 29, 29, Wygładzenie przez ekstrema: - G1: 4, 4, 4, 15 - G2: 21, 21, 25, 25 - G3: 26, 26, 26, 34 slajd 21
22 DC -> > Szumy, błędy i ekstrema -> klastry K1 K2 µ2 µ1 µ3 K3 rozrzut/odstępstwa/ekstrema slajd 22
23 DC -> > Szumy, błędy i ekstrema -> > regresja y Y1 Y1 y = x + 1 X1 x slajd 23
24 Integracja danych - problemy Integracja danych: Dane z różnych źródeł integrowane są w jeden spójny zasób, Integracja schematów: Integracja metadanych pochodzących z różnych źródeł, Identyfikacja znaczenia atrybutów (pól) np., A.cust-id B.cust- # Wykrywanie i eliminacja konfliktów Ten sam obiekt opisywany jest przez różne wartości atrybutów pochodzących z różnych zestawów danych, np. problem stosowanych miar i jednostek (odległość w km czy w milach?). slajd 24
25 Integracja danych redundancja danych Redundancja pojawia się przy integracji danych z wielu źródeł charakteryzujących się odmiennymi schematami: Różne nazwy dla tych samych atrybutów, Atrybuty wywiedzione z atrybutów innych relacji, obiektów, kolekcji (np. suma). Klasyczne formy eliminacji redundancji wykorzystują metody korelacyjne Eliminacja redundancji w sposób istotny wpływa na szybkość działania stosowanych metod eksploracji danych. slajd 25
26 Transformacja danych Eliminacja szumu, uśrednienie, wygładzenie, Agregacje, Generalizacje: concept hierarchy climbing Normalizacje / skalowanie: Skalowanie liniowe min-max, Normalizacja z-score, Skalowanie przez stałą. Konstrukcja nowych atrybutów slajd 26
27 Transformacja danych - normalizacja Skalowanie min-max v = v min maxa min A ' ( _ A _ A) + Normalizacja z-score A new max v v' = µ A δ A new min new_ min A slajd 27 Normalizacja przez stałą µ A v ' = v K np., v'= v 10 Gdzie: - wartość średnia A, δ A - odchylenie standardowe A, K stała, j najmniejsza liczba całkowita, taka że Max( v )<1 j
28 Transformacja danych nowe atrybuty slajd 28
29 Redukcja danych - problemy Hurtownie danych mogą zawierać terabajty wielowymiarowych danych; ich eksploracja może trwać zbyt długo dla potrzeb danego procesu decyzyjnego. Redukcja danych Cel: Generacja mniejszego zbioru danych niż oryginalny dającego te same lub bardzo podobne rezultatu w procesie eksploracji danych Techniki redukcji danych Agregacja Data cube (poziomy agregacji kostki, wymiary kostki) Redukcja wymiaru danych Zmiana reprezentacji danych Dyskretyzacja / generacja hierarchii slajd 29
30 Redukcja danych redukcja wymiaru danych Selekcja cech : Selekcja minimalnego zestawu cech, dla których rozkład prawdopodobieństwa danych klas jest najbardziej podobny do analogicznego rozkładu przy zastosowaniu wszytskich cech, Redukcja liczby wzroców w metodach dopasowania wzorca (pattern matching). Metody heurystyczne: Selekcja krokowa (najlepsza cecha pozostaje), Krokowa eliminacja wsteczna (najgorsza cecha jest eliminowana), Metody łączone, Drzewa decyzyjne. slajd 30
31 Redukcja danych drzewo decyzyjne (indukcja) Początkowy zbiór atrybutów: {A1, A2, A3, A4, A5, A6} A4? A1? A6? Klasa 1 Klasa 2 Klasa 1 Klasa 2 > Końcowy zbiór atrybutów: {A1, A4, A6} slajd 31
32 Redukcja danych kompresja danych Kompresja stratna odtwarzane po kompresji dane stanowią aproksymację danych oryginalnych. W procesie kompresji pozostają elementy najczęściej występujące lub najbardziej istotne ze względu na zadany parametr (np. jakość obrazu). Znane algorytmy kompresji stosujące transformację kosinusów lub falkową wykorzystują dedykowane metody kwantyzacji współczynników transformat. Kompresja bezstratna odtwarzane dane to dane oryginalne Dane oryginalne Przybliżenie danych oryginalnych bezstratna stratna Dane po kompresji slajd 32
33 Redukcja danych PCA Principal Component Analysis Mając N wektorów danych z k-wymiarowej przestrzeni, znaleźć takie c (c<=k) wektorów ortogonalnych, które dobrze (tzn. z dopuszczalnym błędem) reprezentują dane Każdy wektor danych jest liniową kombinacją c wektorów komponentów głównych Transformacja ta stosowana jest dla danych liczbowych Y2 X2 Y1 X1 slajd 33
34 Redukcja danych metody parametryczne Przyjmowany jest model rozkładu wartości atrybutu, np. liniowy, wykładniczy, Parametry modelu są dopasowywane tak, aby odpowiadały danym rzeczywistym, Składowany jest zatem identyfikator typu modelu oraz jego parametry, Przykłady: Regresja liniowa: Y = a X+ b Dwa parametry a i b wytyczają linię prostą. Zatem dla każdego X znane jest Y. Dopasowanie metoda najmniejszych kwadratów z zastosowaniem znanych zestawów danych Y1, Y2,, X1, X2,. Regresja odcinkami liniowa: Y = b0 + b1 X1 + b2 X2. Funkcje nieliniowe: Y=a0 exp(-b0 t)+a1 exp(-b1 t) itd. PRZYKŁADY y y = x + 1 x slajd 34
35 Redukcja danych metody nieparametryczne Nie zakładają modeli, Najczęściej stosowane techniki to: progowanie histogramu, wydzielanie klastrów, próbkowanie HISTOGRAM Grupopowanie elementów histogramu w paczki (granice wyznaczane przez wartości progowe: dolną i górną). Nowa wartość zgrupowanego elementu histogramu to wartość średnia składowych. slajd 35
36 Redukcja danych metody nieparametryczne KLASTRY Klastry stanowią grupy danych w przestrzeni cech. Metody wyznaczania klastrów stanowią jedną z najbardziej popularnych technik stosowanych w eksploracji danych (opis dalej). Każdy klaster może być reprezentowany przez liczbę parametrów (np. wartość średnia), znacznie mniejszą niż liczba jego składowych. Możliwe jest zbudowanie hierarchii klastrów, dzięki czemu możliwe są różne systemy indeksowania. K2 K1 µ2 slajd 36 µ1 µ3 K3
37 Redukcja danych metody nieparametryczne PRÓBKOWANIE Próbkowanie dziedziny danych w celu wygenerowania reprezentacji danych. Problem doboru metody próbkowania losowo, zgodnie z modelem, np. Co drugi element? Optymalny schemat próbkowania. slajd 37 Dane oryginalne Dane po redukcji
38 Redukcja danych dyskretyzacja i kategoryzacja Dyskretyzacja zmniejszenie liczby danych poprzez podział ciągłego zakresu wartości danego atrybutu na skończoną liczbę przedziałów. Każdy przedział może być reprezentowany przez etykiety składowane jako reprezentacja wartości danych. Kategoryzacja zmniejszenie liczby danych przez kategoryzację typu danych argumentu, tj. przejście od wartości bezwzględnej (np. 23 lata) do etykiety zakresu wartości (np. młody ). Kateogryzacja i związny z nią typ danych (categorical) stanowią podstawową operację przygotowania danych dla potrzeb klasyfikacji danych w DM. Stosowane techniki dyskretyzacji i kategoryzacji, to oprócz wymienionych wcześniej, te stosujące progowanie i segmentację danych. slajd 38
39 Redukcja danych dyskretyzacja i kategoryzacja DYSKRETYZACJA PRZEZ MINIMALIZACJĘ ENTROPII Dzieląc zbiór danych D na dwie klasy D1 i D2 zgodnie z obraną wartością progową T, to entropia podziału dana jest wzorem: L( D1) L( D2) H ( D, T ) = H ( D1) + H ( D2) L( D) L( D) Gdzie: H(.) entropia, L(a) liczba elementów a; Dla danej funkcji gęstości prawdopodobieństwa (estymacja przez histogram) p(g) (g=0...k-1), entropię można obliczyć jako: H = K 1 g= 0 p( g) ln( p( g)) T, dla którego H(D,T) jest minimalne jest wybierane jako optymlny prób podziału (binaryzacja). Proces może przebiegać rekurencyjnie aż do spełnienia zadanego kryterium, np. H ( D) H ( D, T ) > ε slajd 39
40 -Metoda modeli Redukcja danych dyskretyzacja i kategoryzacja INNE METODY PROGOWANIA -Metoda Otsu slajd 40 -inne
41 Proces eksploracji danych -Podstawowe zagadnienia -Definicja zadania slajd 41
42 Proces eksploracji danych - podstawowe zagadnienia -Proces eksploracji danych zakłada wyszukiwanie pewnych ukrytych i nieznanych wzorców. Automatyczna realizacja procesu może doprowadzić do bardzo dużej liczby uzyskanych wzorców, często nie istotnych dla rozpatrywanego zadania. -Proces eksploracji danych musi być zatem kontrolowany przez użytkownika. Najczęstsza obecnie realizacja procesu to interaktywne określanie parametrów na każdym etapie (w każdym kroku) eksploracji danych. Realizacja interfejsu obejmuje często dedykowane, graficzne diagramy przepływu działań, bądź ich hierarchiczne uszeregowanie. Inne rozwiązania obejmować mogą opracowanie dedykowanych języków zapytań. slajd 42
43 Proces eksploracji danych zadanie eksploracji Określenie danych związanych z zadaniem Określenie typu poszukiwanej wiedzy Zdefiniowanie posiadanej wiedzy ODKRYWANIE WIEDZY (opracowanie, testowanie i wykorzystanie modelu) Miary i ocena wiedzy odkrytej Wizualizacja odkrytej wiedzy slajd 43
44 Proces eksploracji danych dane Baza danych lub hurtownia Tabela bazy danych, kolekcja, kostka danych Warunki wyboru danych Istotne atrybuty, pola, wymiary Kryteria grupowania danych slajd 44
45 Proces eksploracji danych typ wiedzy Charakterystyki Asocjacje (reguły asocjacyjne) Klasyfikacja Predykcja Segmentacja (klastry) Analiza ekstremów Sekwencje inne slajd 45
46 Proces eksploracji danych posiadana wiedza Hierarchia wiedzy Hierarchia kategorii ogólnych np. ULICA <- MIASTO <- POWIAT <- WOJEWÓDZTWO <- KRAJ Hierarchia kategorii grupowych np. {20-39} = młody, {70-100} = emeryt Hierarchia kategorii operacyjnych np. Adres LOGIN <- WYDZIAŁ <- UNIWERSYTET <- KRAJ Hierarchia reguł np. ZYSK_MIN (X) <= CENA(X, P1) AND KOSZT (X, P2) AND (P1 - P2) < 500PLN slajd 46
47 Proces eksploracji danych miary i ocena Złożoność np. rozmiar reguły asocjacyjnej, wielkość drzewa decyzyjnego, itp., Pewność np. ufność reguły (confidence): P(A B) = n(a AND B)/ n (B), dokładność i błędy klasyfikacji, Użyteczność np. wsparcie reguły/wzorca (support), przekroczenie progu akceptowalności, itp., Nowość wiedza nowa, nieznana, zaskakująca, itp. slajd 47
48 Proces eksploracji danych miary i ocena Klienci kupują i chleb i masło Klienci kupują masło Wsparcie wzorca (support), s, prawdopodobieństwo, że transakcja zawiera {X, Y, Z} Klienci kupują chleb Ufność wzorca (confidence), c, prawdopodobieństwo warunkowe, że transakcja zawierająca {X,Y} zawiera również Z Dla jakich powiązań s i c >=50%? ID transakcji Produkt kupowany 2000 A,B,C 1000 A,C 4000 A,D 5000 B,E,F slajd 48 A C (50%, 66.6%) C A (50%, 100%) Par {A,C} jest 2/4 czyli s=0.5. {A} występuje 3 razy, ale tylko w 2 przypadkach jest i {C} czyli c1=2/3. {C} występuje 2 razy i wówczas występuje również {A}, czyli c2=2/2=1.
49 Proces eksploracji danych miary i ocena lub Lift = correlation, interest slajd 49
50 Proces eksploracji danych miary i ocena Korelacja (interest, correlation, lift) Support{ X Y} Support{ X} Support{ Y} Pozycje X i Y nie są skorelowane jeśli wartość miary jest mniejsza niż 1, są skorelowane w przeciwnym przypadku X Y Z Zbiór Wsparcie Korelacja X,Y 25% 2 X,Z 37,50% 0,9 Y,Z 12,50% 0,57 slajd 50
51 Proces eksploracji danych wizualizacja Wizualizacja danych źródłowych Wizualizacja procesu eksploracji danych Wizualizacja wiedzy: reguły, drzewa, itd., zgodnie z wymienionymi wcześniej rodzajami odkrywanej wiedzy. slajd 51
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska.
 SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
SYSTEMY UCZĄCE SIĘ WYKŁAD 10. PRZEKSZTAŁCANIE ATRYBUTÓW Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska INFORMACJE WSTĘPNE Hipotezy do uczenia się lub tworzenia
1.7. Eksploracja danych: pogłębianie, przeszukiwanie i wyławianie
 Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Wykaz tabel Wykaz rysunków Przedmowa 1. Wprowadzenie 1.1. Wprowadzenie do eksploracji danych 1.2. Natura zbiorów danych 1.3. Rodzaje struktur: modele i wzorce 1.4. Zadania eksploracji danych 1.5. Komponenty
Inżynieria biomedyczna
 Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Inżynieria biomedyczna Projekt Przygotowanie i realizacja kierunku inżynieria biomedyczna studia międzywydziałowe współfinansowany ze środków Unii Europejskiej w ramach Europejskiego Funduszu Społecznego.
Analiza danych i data mining.
 Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
Analiza danych i data mining. mgr Katarzyna Racka Wykładowca WNEI PWSZ w Płocku Przedsiębiorczy student 2016 15 XI 2016 r. Cel warsztatu Przekazanie wiedzy na temat: analizy i zarządzania danymi (data
PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE
 UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
UNIWERSYTET WARMIŃSKO-MAZURSKI W OLSZTYNIE PODYPLOMOWE STUDIA ZAAWANSOWANE METODY ANALIZY DANYCH I DATA MINING W BIZNESIE http://matman.uwm.edu.pl/psi e-mail: psi@matman.uwm.edu.pl ul. Słoneczna 54 10-561
Elementy statystyki wielowymiarowej
 Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
Wnioskowanie_Statystyczne_-_wykład Spis treści 1 Elementy statystyki wielowymiarowej 1.1 Kowariancja i współczynnik korelacji 1.2 Macierz kowariancji 1.3 Dwumianowy rozkład normalny 1.4 Analiza składowych
4.1. Wprowadzenie...70 4.2. Podstawowe definicje...71 4.3. Algorytm określania wartości parametrów w regresji logistycznej...74
 3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
3 Wykaz najważniejszych skrótów...8 Przedmowa... 10 1. Podstawowe pojęcia data mining...11 1.1. Wprowadzenie...12 1.2. Podstawowe zadania eksploracji danych...13 1.3. Główne etapy eksploracji danych...15
SAS wybrane elementy. DATA MINING Część III. Seweryn Kowalski 2006
 SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
SAS wybrane elementy DATA MINING Część III Seweryn Kowalski 2006 Algorytmy eksploracji danych Algorytm eksploracji danych jest dobrze zdefiniowaną procedurą, która na wejściu otrzymuje dane, a na wyjściu
Hierarchiczna analiza skupień
 Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Hierarchiczna analiza skupień Cel analizy Analiza skupień ma na celu wykrycie w zbiorze obserwacji klastrów, czyli rozłącznych podzbiorów obserwacji, wewnątrz których obserwacje są sobie w jakimś określonym
Zalew danych skąd się biorą dane? są generowane przez banki, ubezpieczalnie, sieci handlowe, dane eksperymentalne, Web, tekst, e_handel
 według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
według przewidywań internetowego magazynu ZDNET News z 8 lutego 2001 roku eksploracja danych (ang. data mining ) będzie jednym z najbardziej rewolucyjnych osiągnięć następnej dekady. Rzeczywiście MIT Technology
Szczegółowy opis przedmiotu zamówienia
 ZP/ITS/19/2013 SIWZ Załącznik nr 1.1 do Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych dla studentów
ZP/ITS/19/2013 SIWZ Załącznik nr 1.1 do Szczegółowy opis przedmiotu zamówienia Przedmiotem zamówienia jest: Przygotowanie zajęć dydaktycznych w postaci kursów e-learningowych przeznaczonych dla studentów
Eksploracja danych (data mining)
") Eksploracja (data mining) Tadeusz Pankowski www.put.poznan.pl/~pankowsk Czym jest eksploracja? Eksploracja oznacza wydobywanie wiedzy z dużych zbiorów. Eksploracja badanie, przeszukiwanie; np. dziewiczych
Eksploracja (data mining) Tadeusz Pankowski www.put.poznan.pl/~pankowsk Czym jest eksploracja? Eksploracja oznacza wydobywanie wiedzy z dużych zbiorów. Eksploracja badanie, przeszukiwanie; np. dziewiczych
Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych. Data Mining Wykład 2
 Data Mining Wykład 2 Odkrywanie asocjacji Plan wykładu Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych Geneza problemu Geneza problemu odkrywania reguł
Data Mining Wykład 2 Odkrywanie asocjacji Plan wykładu Wprowadzenie Sformułowanie problemu Typy reguł asocjacyjnych Proces odkrywania reguł asocjacyjnych Geneza problemu Geneza problemu odkrywania reguł
Data Mining Wykład 1. Wprowadzenie do Eksploracji Danych. Prowadzący. Dr inż. Jacek Lewandowski
 Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Data Mining Wykład 1 Wprowadzenie do Eksploracji Danych Prowadzący Dr inż. Jacek Lewandowski Katedra Genetyki Wydział Biologii i Hodowli Zwierząt Uniwersytet Przyrodniczy we Wrocławiu ul. Kożuchowska 7,
Data Mining Kopalnie Wiedzy
 Data Mining Kopalnie Wiedzy Janusz z Będzina Instytut Informatyki i Nauki o Materiałach Sosnowiec, 30 listopada 2006 Kopalnie złota XIX Wiek. Odkrycie pokładów złota spowodowało napływ poszukiwaczy. Przeczesywali
Data Mining Kopalnie Wiedzy Janusz z Będzina Instytut Informatyki i Nauki o Materiałach Sosnowiec, 30 listopada 2006 Kopalnie złota XIX Wiek. Odkrycie pokładów złota spowodowało napływ poszukiwaczy. Przeczesywali
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, Spis treści
 Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Automatyczne rozpoznawanie mowy - wybrane zagadnienia / Ryszard Makowski. Wrocław, 2011 Spis treści Przedmowa 11 Rozdział 1. WPROWADZENIE 13 1.1. Czym jest automatyczne rozpoznawanie mowy 13 1.2. Poziomy
Analiza danych. http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU
 Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Analiza danych Wstęp Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/ TEMATYKA PRZEDMIOTU Różne aspekty analizy danych Reprezentacja graficzna danych Metody statystyczne: estymacja parametrów
Mail: Pokój 214, II piętro
 Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Wykład 2 Mail: agnieszka.nowak@us.edu.pl Pokój 214, II piętro http://zsi.tech.us.edu.pl/~nowak Predykcja zdolność do wykorzystania wiedzy zgromadzonej w systemie do przewidywania wartości dla nowych danych,
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Przykład eksploracji danych o naturze statystycznej Próba 1 wartości zmiennej losowej odległość
 Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Dwie metody Klasyczna metoda histogramu jako narzędzie do postawienia hipotezy, jaki rozkład prawdopodobieństwa pasuje do danych Indukcja drzewa decyzyjnego jako metoda wykrycia klasyfikatora ukrytego
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne)
") Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
Klasyfikacja obiektów Drzewa decyzyjne (drzewa klasyfikacyjne) Tadeusz Pankowski www.put.poznan.pl/~tadeusz.pankowski Klasyfikacja i predykcja. Odkrywaniem reguł klasyfikacji nazywamy proces znajdowania
WSTĘP I TAKSONOMIA METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING. Adrian Horzyk. Akademia Górniczo-Hutnicza
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING WSTĘP I TAKSONOMIA Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej Katedra
Spis treści. Przedmowa... XI. Rozdział 1. Pomiar: jednostki miar... 1. Rozdział 2. Pomiar: liczby i obliczenia liczbowe... 16
 Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
Spis treści Przedmowa.......................... XI Rozdział 1. Pomiar: jednostki miar................. 1 1.1. Wielkości fizyczne i pozafizyczne.................. 1 1.2. Spójne układy miar. Układ SI i jego
HURTOWNIE DANYCH I BUSINESS INTELLIGENCE
 BAZY DANYCH HURTOWNIE DANYCH I BUSINESS INTELLIGENCE Akademia Górniczo-Hutnicza w Krakowie Adrian Horzyk horzyk@agh.edu.pl Google: Horzyk HURTOWNIE DANYCH Hurtownia danych (Data Warehouse) to najczęściej
BAZY DANYCH HURTOWNIE DANYCH I BUSINESS INTELLIGENCE Akademia Górniczo-Hutnicza w Krakowie Adrian Horzyk horzyk@agh.edu.pl Google: Horzyk HURTOWNIE DANYCH Hurtownia danych (Data Warehouse) to najczęściej
Klasyfikator. ˆp(k x) = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,
 = 1 K. I(ρ(x,x i ) ρ(x,x (K) ))I(y i =k),k =1,...,L,") Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
Klasyfikator Jedną z najistotniejszych nieparametrycznych metod klasyfikacji jest metoda K-najbliższych sąsiadów, oznaczana przez K-NN. W metodzie tej zaliczamy rozpoznawany obiekt do tej klasy, do której
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ. Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska
 SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
SYSTEMY UCZĄCE SIĘ WYKŁAD 4. DRZEWA REGRESYJNE, INDUKCJA REGUŁ Częstochowa 2014 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska DRZEWO REGRESYJNE Sposób konstrukcji i przycinania
OLAP i hurtownie danych c.d.
 OLAP i hurtownie danych c.d. Przypomnienie OLAP -narzędzia analizy danych Hurtownie danych -duże bazy danych zorientowane tematycznie, nieulotne, zmienne w czasie, wspierjące procesy podejmowania decyzji
OLAP i hurtownie danych c.d. Przypomnienie OLAP -narzędzia analizy danych Hurtownie danych -duże bazy danych zorientowane tematycznie, nieulotne, zmienne w czasie, wspierjące procesy podejmowania decyzji
Algorytmy klasyfikacji
 Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
Algorytmy klasyfikacji Konrad Miziński Instytut Informatyki Politechnika Warszawska 6 maja 2015 1 Wnioskowanie 2 Klasyfikacja Zastosowania 3 Drzewa decyzyjne Budowa Ocena jakości Przycinanie 4 Lasy losowe
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH
 INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
INDUKOWANE REGUŁY DECYZYJNE ALORYTM APRIORI JAROSŁAW FIBICH 1. Czym jest eksploracja danych Eksploracja danych definiowana jest jako zbiór technik odkrywania nietrywialnych zależności i schematów w dużych
Elementy modelowania matematycznego
 Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Elementy modelowania matematycznego Modelowanie algorytmów klasyfikujących. Podejście probabilistyczne. Naiwny klasyfikator bayesowski. Modelowanie danych metodą najbliższych sąsiadów. Jakub Wróblewski
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, Spis treści
 Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
Statystyka w zarzadzaniu / Amir D. Aczel, Jayavel Sounderpandian. Wydanie 2. Warszawa, 2018 Spis treści Przedmowa 13 O Autorach 15 Przedmowa od Tłumacza 17 1. Wprowadzenie i statystyka opisowa 19 1.1.
Wprowadzenie do technologii informacyjnej.
 Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Wprowadzenie do technologii informacyjnej. Data mining i jego biznesowe zastosowania dr Tomasz Jach Definicje Eksploracja danych polega na torturowaniu danych tak długo, aż zaczną zeznawać. Eksploracja
Aproksymacja funkcji a regresja symboliczna
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(x), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(x), zwaną funkcją aproksymującą
Data Mining Wykład 9. Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu
 Grupowanie hierarchiczne O-Cluster. Plan wykładu. Sformułowanie problemu") Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Data Mining Wykład 9 Analiza skupień (grupowanie) Grupowanie hierarchiczne O-Cluster Plan wykładu Wprowadzanie Definicja problemu Klasyfikacja metod grupowania Grupowanie hierarchiczne Sformułowanie problemu
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Agnieszka Nowak Brzezińska
 Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
Agnieszka Nowak Brzezińska jeden z algorytmów regresji nieparametrycznej używanych w statystyce do prognozowania wartości pewnej zmiennej losowej. Może również byd używany do klasyfikacji. - Założenia
TRANSFORMACJE I JAKOŚĆ DANYCH
 METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
METODY INŻYNIERII WIEDZY KNOWLEDGE ENGINEERING AND DATA MINING TRANSFORMACJE I JAKOŚĆ DANYCH Adrian Horzyk Akademia Górniczo-Hutnicza Wydział Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej
Proces odkrywania wiedzy z baz danych
 Proces odkrywania wiedzy z baz danych Wydział Informatyki Politechnika Białostocka Marcin Czajkowski email: m.czajkowski@pb.edu.pl Świat pełen danych Świat pełen danych Możliwości analizowania i zrozumienia
Proces odkrywania wiedzy z baz danych Wydział Informatyki Politechnika Białostocka Marcin Czajkowski email: m.czajkowski@pb.edu.pl Świat pełen danych Świat pełen danych Możliwości analizowania i zrozumienia
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Klasyfikatory: k-nn oraz naiwny Bayesa. Agnieszka Nowak Brzezińska Wykład IV
 Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
Klasyfikatory: k-nn oraz naiwny Bayesa Agnieszka Nowak Brzezińska Wykład IV Naiwny klasyfikator Bayesa Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną
AUTOMATYKA INFORMATYKA
 AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
AUTOMATYKA INFORMATYKA Technologie Informacyjne Sieć Semantyczna Przetwarzanie Języka Naturalnego Internet Edytor Serii: Zdzisław Kowalczuk Inteligentne wydobywanie informacji z internetowych serwisów
Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji
 Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Analiza składników podstawowych - wprowadzenie (Principal Components Analysis
Monitorowanie i Diagnostyka w Systemach Sterowania na studiach II stopnia specjalności: Systemy Sterowania i Podejmowania Decyzji Analiza składników podstawowych - wprowadzenie (Principal Components Analysis
Wprowadzenie do technologii Business Intelligence i hurtowni danych
 Wprowadzenie do technologii Business Intelligence i hurtowni danych 1 Plan rozdziału 2 Wprowadzenie do Business Intelligence Hurtownie danych Produkty Oracle dla Business Intelligence Business Intelligence
Wprowadzenie do technologii Business Intelligence i hurtowni danych 1 Plan rozdziału 2 Wprowadzenie do Business Intelligence Hurtownie danych Produkty Oracle dla Business Intelligence Business Intelligence
Metody Inżynierii Wiedzy
 Metody Inżynierii Wiedzy Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie AGH University of Science and Technology Mateusz Burcon Kraków, czerwiec 2017 Wykorzystane technologie Python 3.4
Metody Inżynierii Wiedzy Akademia Górniczo-Hutnicza im. Stanisława Staszica w Krakowie AGH University of Science and Technology Mateusz Burcon Kraków, czerwiec 2017 Wykorzystane technologie Python 3.4
Hurtownie danych. Projektowanie hurtowni: modele wielowymiarowe. Modelowanie punktowe. Operacje OLAP na kostkach. http://zajecia.jakubw.
 Hurtownie danych Projektowanie hurtowni: modele wielowymiarowe. Modelowanie punktowe. Operacje OLAP na kostkach. http://zajecia.jakubw.pl/hur UZASADNIENIE BIZNESOWE Po co nam hurtownia danych? Jakie mogą
Hurtownie danych Projektowanie hurtowni: modele wielowymiarowe. Modelowanie punktowe. Operacje OLAP na kostkach. http://zajecia.jakubw.pl/hur UZASADNIENIE BIZNESOWE Po co nam hurtownia danych? Jakie mogą
Analiza metod wykrywania przekazów steganograficznych. Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl
 Analiza metod wykrywania przekazów steganograficznych Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl Plan prezentacji Wprowadzenie Cel pracy Tezy pracy Koncepcja systemu Typy i wyniki testów Optymalizacja
Analiza metod wykrywania przekazów steganograficznych Magdalena Pejas Wydział EiTI PW magdap7@gazeta.pl Plan prezentacji Wprowadzenie Cel pracy Tezy pracy Koncepcja systemu Typy i wyniki testów Optymalizacja
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych
 Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Algorytmy decyzyjne będące alternatywą dla sieci neuronowych Piotr Dalka Przykładowe algorytmy decyzyjne Sztuczne sieci neuronowe Algorytm k najbliższych sąsiadów Kaskada klasyfikatorów AdaBoost Naiwny
Indeksy w bazach danych. Motywacje. Techniki indeksowania w eksploracji danych. Plan prezentacji. Dotychczasowe prace badawcze skupiały się na
 Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Techniki indeksowania w eksploracji danych Maciej Zakrzewicz Instytut Informatyki Politechnika Poznańska Plan prezentacji Zastosowania indeksów w systemach baz danych Wprowadzenie do metod eksploracji
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Pattern Classification
 Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taken from Pattern Classification (2nd ed) by R. O. Duda, P. E. Hart and D. G. Stork, John Wiley & Sons, 2000 with the permission of the authors
Hurtownie danych i business intelligence - wykład II. Zagadnienia do omówienia. Miejsce i rola HD w firmie
 Hurtownie danych i business intelligence - wykład II Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2005-2012 Zagadnienia do omówienia 1. Miejsce i rola w firmie 2. Przegląd architektury
Hurtownie danych i business intelligence - wykład II Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl oprac. Wrocław 2005-2012 Zagadnienia do omówienia 1. Miejsce i rola w firmie 2. Przegląd architektury
Usługi analityczne budowa kostki analitycznej Część pierwsza.
 Usługi analityczne budowa kostki analitycznej Część pierwsza. Wprowadzenie W wielu dziedzinach działalności człowieka analiza zebranych danych jest jednym z najważniejszych mechanizmów podejmowania decyzji.
Usługi analityczne budowa kostki analitycznej Część pierwsza. Wprowadzenie W wielu dziedzinach działalności człowieka analiza zebranych danych jest jednym z najważniejszych mechanizmów podejmowania decyzji.
Analiza głównych składowych- redukcja wymiaru, wykł. 12
 Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
Analiza głównych składowych- redukcja wymiaru, wykł. 12 Joanna Jędrzejowicz Instytut Informatyki Konieczność redukcji wymiaru w eksploracji danych bazy danych spotykane w zadaniach eksploracji danych mają
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Modelowanie glikemii w procesie insulinoterapii
 Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
Dawid Kaliszewski Modelowanie glikemii w procesie insulinoterapii Promotor dr hab. inż. Zenon Gniazdowski Cel pracy Zbudowanie modelu predykcyjnego przyszłych wartości glikemii diabetyka leczonego za pomocą
SZKOLENIA SAS. ONKO.SYS Kompleksowa infrastruktura inforamtyczna dla badań nad nowotworami CENTRUM ONKOLOGII INSTYTUT im. Marii Skłodowskiej Curie
 SZKOLENIA SAS ONKO.SYS Kompleksowa infrastruktura inforamtyczna dla badań nad nowotworami CENTRUM ONKOLOGII INSTYTUT im. Marii Skłodowskiej Curie DANIEL KUBIK ŁUKASZ LESZEWSKI ROLE ROLE UŻYTKOWNIKÓW MODUŁU
SZKOLENIA SAS ONKO.SYS Kompleksowa infrastruktura inforamtyczna dla badań nad nowotworami CENTRUM ONKOLOGII INSTYTUT im. Marii Skłodowskiej Curie DANIEL KUBIK ŁUKASZ LESZEWSKI ROLE ROLE UŻYTKOWNIKÓW MODUŁU
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji
 Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Konkurs z przedmiotu eksploracja i analiza danych: problem regresji i klasyfikacji Michał Witczak Data Mining 20 maja 2012 r. 1. Wstęp Dostarczone zostały nam 4 pliki, z których dwa stanowiły zbiory uczące
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych. Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS
 Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
Algorytmy klasteryzacji jako metoda dyskretyzacji w algorytmach eksploracji danych Łukasz Przybyłek, Jakub Niwa Studenckie Koło Naukowe BRAINS Dyskretyzacja - definicja Dyskretyzacja - zamiana atrybutów
ALGORYTM RANDOM FOREST
 SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
SKRYPT PRZYGOTOWANY NA ZAJĘCIA INDUKOWANYCH REGUŁ DECYZYJNYCH PROWADZONYCH PRZEZ PANA PAWŁA WOJTKIEWICZA ALGORYTM RANDOM FOREST Katarzyna Graboś 56397 Aleksandra Mańko 56699 2015-01-26, Warszawa ALGORYTM
Ćwiczenia z Zaawansowanych Systemów Baz Danych
 Ćwiczenia z Zaawansowanych Systemów Baz Danych Hurtownie danych Zad 1. Projekt schematu hurtowni danych W źródłach danych dostępne są następujące informacje dotyczące operacji bankowych: Klienci banku
Ćwiczenia z Zaawansowanych Systemów Baz Danych Hurtownie danych Zad 1. Projekt schematu hurtowni danych W źródłach danych dostępne są następujące informacje dotyczące operacji bankowych: Klienci banku
Algorytmy metaheurystyczne Wykład 11. Piotr Syga
 Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Algorytmy metaheurystyczne Wykład 11 Piotr Syga 22.05.2017 Drzewa decyzyjne Idea Cel Na podstawie przesłanek (typowo zbiory rozmyte) oraz zbioru wartości w danych testowych, w oparciu o wybrane miary,
Eksploracja Danych. wykład 4. Sebastian Zając. 10 maja 2017 WMP.SNŚ UKSW. Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja / 18
 Eksploracja Danych 10 maja / 18") Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Eksploracja Danych wykład 4 Sebastian Zając WMP.SNŚ UKSW 10 maja 2017 Sebastian Zając (WMP.SNŚ UKSW) Eksploracja Danych 10 maja 2017 1 / 18 Klasyfikacja danych Klasyfikacja Najczęściej stosowana (najstarsza)
Systemy uczące się wykład 2
 Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
Systemy uczące się wykład 2 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 19 X 2018 Podstawowe definicje Fakt; Przesłanka; Konkluzja; Reguła; Wnioskowanie. Typy wnioskowania
1. Odkrywanie asocjacji
 1. 2. Odkrywanie asocjacji...1 Algorytmy...1 1. A priori...1 2. Algorytm FP-Growth...2 3. Wykorzystanie narzędzi Oracle Data Miner i Rapid Miner do odkrywania reguł asocjacyjnych...2 3.1. Odkrywanie reguł
1. 2. Odkrywanie asocjacji...1 Algorytmy...1 1. A priori...1 2. Algorytm FP-Growth...2 3. Wykorzystanie narzędzi Oracle Data Miner i Rapid Miner do odkrywania reguł asocjacyjnych...2 3.1. Odkrywanie reguł
HURTOWNIE DANYCH Dzięki uprzejmości Dr. Jakuba Wróblewskiego
 HURTOWNIE DANYCH Dzięki uprzejmości Dr. Jakuba Wróblewskiego http://www.jakubw.pl/zajecia/hur/bi.pdf http://www.jakubw.pl/zajecia/hur/dw.pdf http://www.jakubw.pl/zajecia/hur/dm.pdf http://www.jakubw.pl/zajecia/hur/
HURTOWNIE DANYCH Dzięki uprzejmości Dr. Jakuba Wróblewskiego http://www.jakubw.pl/zajecia/hur/bi.pdf http://www.jakubw.pl/zajecia/hur/dw.pdf http://www.jakubw.pl/zajecia/hur/dm.pdf http://www.jakubw.pl/zajecia/hur/
mgr inż. Magdalena Deckert Poznań, r. Metody przyrostowego uczenia się ze strumieni danych.
 mgr inż. Magdalena Deckert Poznań, 30.11.2010r. Metody przyrostowego uczenia się ze strumieni danych. Plan prezentacji Wstęp Concept drift i typy zmian Algorytmy przyrostowego uczenia się ze strumieni
mgr inż. Magdalena Deckert Poznań, 30.11.2010r. Metody przyrostowego uczenia się ze strumieni danych. Plan prezentacji Wstęp Concept drift i typy zmian Algorytmy przyrostowego uczenia się ze strumieni
ZASTOSOWANIE TECHNIK CHEMOMETRYCZNYCH W BADANIACH ŚRODOWISKA. dr inż. Aleksander Astel
 ZASTOSOWANIE TECHNIK CHEMOMETRYCZNYCH W BADANIACH ŚRODOWISKA dr inż. Aleksander Astel Gdańsk, 22.12.2004 CHEMOMETRIA dziedzina nauki i techniki zajmująca się wydobywaniem użytecznej informacji z wielowymiarowych
ZASTOSOWANIE TECHNIK CHEMOMETRYCZNYCH W BADANIACH ŚRODOWISKA dr inż. Aleksander Astel Gdańsk, 22.12.2004 CHEMOMETRIA dziedzina nauki i techniki zajmująca się wydobywaniem użytecznej informacji z wielowymiarowych
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Zmienne zależne i niezależne
 Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Analiza kanoniczna Motywacja (1) 2 Często w badaniach spotykamy problemy badawcze, w których szukamy zakresu i kierunku zależności pomiędzy zbiorami zmiennych: { X i Jak oceniać takie 1, X 2,..., X p }
Statystyka. Rozkład prawdopodobieństwa Testowanie hipotez. Wykład III ( )
") Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Ewelina Dziura Krzysztof Maryański
 Ewelina Dziura Krzysztof Maryański 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład
Ewelina Dziura Krzysztof Maryański 1. Wstęp - eksploracja danych 2. Proces Eksploracji danych 3. Reguły asocjacyjne budowa, zastosowanie, pozyskiwanie 4. Algorytm Apriori i jego modyfikacje 5. Przykład
Hurtownie danych. Przetwarzanie zapytań. http://zajecia.jakubw.pl/hur ZAPYTANIA NA ZAPLECZU
 Hurtownie danych Przetwarzanie zapytań. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/hur ZAPYTANIA NA ZAPLECZU Magazyny danych operacyjnych, źródła Centralna hurtownia danych Hurtownie
Hurtownie danych Przetwarzanie zapytań. Jakub Wróblewski jakubw@pjwstk.edu.pl http://zajecia.jakubw.pl/hur ZAPYTANIA NA ZAPLECZU Magazyny danych operacyjnych, źródła Centralna hurtownia danych Hurtownie
STATYSTYKA MATEMATYCZNA
 STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
STATYSTYKA MATEMATYCZNA 1. Wykład wstępny. Teoria prawdopodobieństwa i elementy kombinatoryki 2. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5.
Sylabus modułu kształcenia na studiach wyższych. Nazwa Wydziału. Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia.
 Załącznik nr 4 do zarządzenia nr 12 Rektora UJ z 15 lutego 2012 r. Sylabus modułu kształcenia na studiach wyższych Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Wydział Matematyki
Załącznik nr 4 do zarządzenia nr 12 Rektora UJ z 15 lutego 2012 r. Sylabus modułu kształcenia na studiach wyższych Nazwa Wydziału Nazwa jednostki prowadzącej moduł Nazwa modułu kształcenia Wydział Matematyki
Eksploracja danych - wykład II
 - wykład 1/29 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Październik 2015 - wykład 2/29 W kontekście odkrywania wiedzy wykład - wykład 3/29 CRISP-DM - standaryzacja
- wykład 1/29 wykład - wykład Instytut Informatyki Teoretycznej i Stosowanej Politechnika Częstochowska Październik 2015 - wykład 2/29 W kontekście odkrywania wiedzy wykład - wykład 3/29 CRISP-DM - standaryzacja
Systemy uczące się Lab 4
 Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Systemy uczące się Lab 4 dr Przemysław Juszczuk Katedra Inżynierii Wiedzy, Uniwersytet Ekonomiczny 26 X 2018 Projekt zaliczeniowy Podstawą zaliczenia ćwiczeń jest indywidualne wykonanie projektu uwzględniającego
Agnieszka Nowak Brzezińska Wykład III
 Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
Agnieszka Nowak Brzezińska Wykład III Naiwny klasyfikator bayesowski jest prostym probabilistycznym klasyfikatorem. Zakłada się wzajemną niezależność zmiennych niezależnych (tu naiwność) Bardziej opisowe
data mining machine learning data science
 data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
data mining machine learning data science deep learning, AI, statistics, IoT, operations research, applied mathematics KISIM, WIMiIP, AGH 1 Machine Learning / Data mining / Data science Uczenie maszynowe
Testowanie hipotez statystycznych
 9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
9 października 2008 ...czyli definicje na rozgrzewkę n-elementowa próba losowa - wektor n zmiennych losowych (X 1,..., X n ); intuicyjnie: wynik n eksperymentów realizacja próby (X 1,..., X n ) w ω Ω :
Transformacja wiedzy w budowie i eksploatacji maszyn
 Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
Uniwersytet Technologiczno Przyrodniczy im. Jana i Jędrzeja Śniadeckich w Bydgoszczy Wydział Mechaniczny Transformacja wiedzy w budowie i eksploatacji maszyn Bogdan ŻÓŁTOWSKI W pracy przedstawiono proces
KLASYFIKACJA. Słownik języka polskiego
 KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
KLASYFIKACJA KLASYFIKACJA Słownik języka polskiego Klasyfikacja systematyczny podział przedmiotów lub zjawisk na klasy, działy, poddziały, wykonywany według określonej zasady Klasyfikacja polega na przyporządkowaniu
Dostawa oprogramowania. Nr sprawy: ZP /15
 ........ (pieczątka adresowa Oferenta) Zamawiający: Państwowa Wyższa Szkoła Zawodowa w Nowym Sączu, ul. Staszica,33-300 Nowy Sącz. Strona: z 5 Arkusz kalkulacyjny określający minimalne parametry techniczne
........ (pieczątka adresowa Oferenta) Zamawiający: Państwowa Wyższa Szkoła Zawodowa w Nowym Sączu, ul. Staszica,33-300 Nowy Sącz. Strona: z 5 Arkusz kalkulacyjny określający minimalne parametry techniczne
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817
 Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Analiza Danych Sprawozdanie regresja Marek Lewandowski Inf 59817 Zadanie 1: wiek 7 8 9 1 11 11,5 12 13 14 14 15 16 17 18 18,5 19 wzrost 12 122 125 131 135 14 142 145 15 1 154 159 162 164 168 17 Wykres
Testowanie hipotez statystycznych
 Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
w analizie wyników badań eksperymentalnych, w problemach modelowania zjawisk fizycznych, w analizie obserwacji statystycznych.
 Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
Aproksymacja funkcji a regresja symboliczna Problem aproksymacji funkcji polega na tym, że funkcję F(), znaną lub określoną tablicą wartości, należy zastąpić inną funkcją, f(), zwaną funkcją aproksymującą
SZTUCZNA INTELIGENCJA
 SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
SZTUCZNA INTELIGENCJA WYKŁAD 4. UCZENIE SIĘ INDUKCYJNE Częstochowa 24 Dr hab. inż. Grzegorz Dudek Wydział Elektryczny Politechnika Częstochowska WSTĘP Wiedza pozyskana przez ucznia ma charakter odwzorowania
Zastosowania metod odkrywania wiedzy do diagnostyki maszyn i procesów
 Zastosowania metod odkrywania wiedzy do diagnostyki maszyn i procesów Wojciech Moczulski Politechnika Śląska Katedra Podstaw Konstrukcji Maszyn Sztuczna inteligencja w automatyce i robotyce Zielona Góra,
Zastosowania metod odkrywania wiedzy do diagnostyki maszyn i procesów Wojciech Moczulski Politechnika Śląska Katedra Podstaw Konstrukcji Maszyn Sztuczna inteligencja w automatyce i robotyce Zielona Góra,
Hurtownie danych i business intelligence. Plan na dziś : Wprowadzenie do przedmiotu
 i business intelligence Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl Wrocław 2005-2012 Plan na dziś : 1. Wprowadzenie do przedmiotu (co będzie omawiane oraz jak będę weryfikował zdobytą wiedzę
i business intelligence Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl Wrocław 2005-2012 Plan na dziś : 1. Wprowadzenie do przedmiotu (co będzie omawiane oraz jak będę weryfikował zdobytą wiedzę
Analiza składowych głównych
 Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
Analiza składowych głównych Wprowadzenie (1) W przypadku regresji naszym celem jest predykcja wartości zmiennej wyjściowej za pomocą zmiennych wejściowych, wykrycie związku między wielkościami wejściowymi
METODY STATYSTYCZNE W BIOLOGII
 METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
METODY STATYSTYCZNE W BIOLOGII 1. Wykład wstępny 2. Populacje i próby danych 3. Testowanie hipotez i estymacja parametrów 4. Planowanie eksperymentów biologicznych 5. Najczęściej wykorzystywane testy statystyczne
Analiza składowych głównych. Wprowadzenie
 Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Wprowadzenie jest techniką redukcji wymiaru. Składowe główne zostały po raz pierwszy zaproponowane przez Pearsona(1901), a następnie rozwinięte przez Hotellinga (1933). jest zaliczana do systemów uczących
Analiza skupień. Analiza Skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania
 Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Analiza skupień W sztucznej inteligencji istotną rolę ogrywają algorytmy grupowania Analiza Skupień Elementy składowe procesu grupowania obiekt Ekstrakcja cech Sprzężenie zwrotne Grupowanie klastry Reprezentacja
Cyfrowe przetwarzanie obrazów i sygnałów Wykład 8 AiR III
 1 Niniejszy dokument zawiera materiały do wykładu z przedmiotu Cyfrowe Przetwarzanie Obrazów i Sygnałów. Jest on udostępniony pod warunkiem wykorzystania wyłącznie do własnych, prywatnych potrzeb i może
1 Niniejszy dokument zawiera materiały do wykładu z przedmiotu Cyfrowe Przetwarzanie Obrazów i Sygnałów. Jest on udostępniony pod warunkiem wykorzystania wyłącznie do własnych, prywatnych potrzeb i może
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA
 METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
METODY CHEMOMETRYCZNE W IDENTYFIKACJI ŹRÓDEŁ POCHODZENIA AMFETAMINY Waldemar S. Krawczyk Centralne Laboratorium Kryminalistyczne Komendy Głównej Policji, Warszawa (praca obroniona na Wydziale Chemii Uniwersytetu
Hurtownie danych i business intelligence. Plan na dziś : Wprowadzenie do przedmiotu
 i business intelligence Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl Wrocław 2005-2007 Plan na dziś : 1. Wprowadzenie do przedmiotu (co będzie omawiane oraz jak będę weryfikował zdobytą wiedzę
i business intelligence Paweł Skrobanek, C-3 pok. 321 pawel.skrobanek@pwr.wroc.pl Wrocław 2005-2007 Plan na dziś : 1. Wprowadzenie do przedmiotu (co będzie omawiane oraz jak będę weryfikował zdobytą wiedzę
Metody eksploracji danych. Reguły asocjacyjne
 Metody eksploracji danych Reguły asocjacyjne Analiza podobieństw i koszyka sklepowego Analiza podobieństw jest badaniem atrybutów lub cech, które są powiązane ze sobą. Metody analizy podobieństw, znane
Metody eksploracji danych Reguły asocjacyjne Analiza podobieństw i koszyka sklepowego Analiza podobieństw jest badaniem atrybutów lub cech, które są powiązane ze sobą. Metody analizy podobieństw, znane
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Hurtownie danych. Wprowadzenie do systemów typu Business Intelligence
 Hurtownie danych Wprowadzenie do systemów typu Business Intelligence Krzysztof Goczyła Teresa Zawadzka Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki Politechnika
Hurtownie danych Wprowadzenie do systemów typu Business Intelligence Krzysztof Goczyła Teresa Zawadzka Katedra Inżynierii Oprogramowania Wydział Elektroniki, Telekomunikacji i Informatyki Politechnika