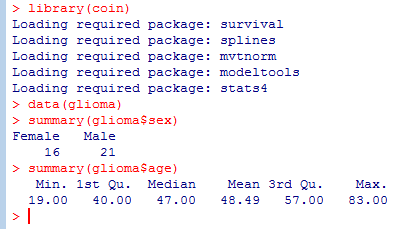
Agnieszka Nowak - Brzezińska
|
|
|
- Beata Szydłowska
- 8 lat temu
- Przeglądów:
Transkrypt
1 Agnieszka Nowak - Brzezińska

2
3
4 Gdy zbiór zdarzeń elementarnych jest skończony, odwzorowywanie go w zbiór liczb (czyli tworzenie zmiennej losowej) może być mniej użyteczne niż w przypadku zmiennej losowej ciągłej.
5 Jeśli zbiór zdarzeń elementarnych nie wykazuje naturalnego uporządkowania, mówimy o skali nominalnej Przykłady: grupa krwi (0,A,B,AB), rozpoznanie, czynnik etiologiczny, sympatie polityczne (PO,PiS,PSL,...), wyznanie, narodowość, rasa...
6 Gdy w zbiorze zdarzeń istnieje naturalne uporządkowanie, ale wprowadzanie odległości nie ma sensu, mamy do czynienia ze skalą porządkową. Przykłady: wynik leczenia (pogorszenie,b.z., poprawa), wykształcenie (brak, podst., średnie, wyższe), WBC (poniżej, w normie, powyżej)
7 Gdy w skończonym zbiorze zdarzeń elementarnych istnieje odległość, prezentacja wyników w postaci zmiennej losowej jest w pełni uzasadniona. Przykłady: tętno, WBC (tys./mm 3 ), liczba dzieci Gdy liczba możliwych wartości jest duża, traktujemy taką zmienną jako ciągłą.
8 Pojęcie skali pomiarowej ma zastosowanie nie tylko do zmiennych losowych (wyników pomiarów), ale także w odniesieniu do wielkości kontrolowanych w eksperymencie (czynników).
.")
9 Pojecie hipotezy statystycznej ewoluowało przez setki lat. Pierwsze zachowane wzmianki o koncepcie hipotezy można znaleźć w pracy Teoria Matematyki greckiego filozofa Geminus a (pierwsze dziesięciolecia naszej ery). Termin hipoteza był przez wieki używany w astrologii oraz fizyce. Przykładami sa prace Gottfrieda Wilhelma Leibniz a ( Nowe hipotezy fizyczne, 1671) oraz Isaaca Newtona ( Hipotezy o świetle, 1675). Wzmianki o pierwszej hipotezie zweryfikowanej na gruncie analizy statystycznej dotyczą pracy medyka Johna Arbuthnota ( ), który w roku 1710 opublikował w Royal Society pracę An argument for Divine Providence, taken from the constant regularity observ d in the births of both sexes. W pracy tej przedstawił roczne liczby urodzeń chłopców oraz dziewcząt w Londynie z lat oraz zauważył, że w każdym roku rodziło sie więcej chłopców niż dziewcząt. Obliczając stosowne prawdopodobieństwa na ich podstawie stwierdził, że częstość urodzin chłopców jest statystycznie istotnie większa niż częstość urodzin dziewcząt.
")
10 Przez kolejny wiek uczeni stawiając i weryfikując hipotezy statystyczne kierowali się intuicją. Dopiero w latach dwudziestych XX wieku aksjomatyczne podstawy dla zagadnienia testowania opracowali Jerzy Spława-Neyman (matematyk polskiego pochodzenia) i Egon Pearson (syn znakomitego statystyka Karla Pearsona).

11 hipotezy proste hipotezy złożone hipotezy parametryczne hipotezy nieparametryczne
12 Hipoteza statystyczna: każdy sąd o populacji generalnej wydany na podstawie badań częściowych, dający się zweryfikować metodami statystycznymi, czyli na podstawie wyników badań próby. Hipoteza parametryczna: hipoteza dotycząca parametrów rozkładu statystycznego. Hipotezy weryfikujemy za pomocą testów statystycznych. Test statystyczny: metoda postępowania, która każdej próbce x 1, x 2,...,x n przyporządkowuje z ustalonym prawdopodobieństwem decyzje odrzucenia lub przyjęcia sprawdzanej hipotezy.
13 Test statystyczny to procedura pozwalająca oszacować prawdopodobieństwo spełnienia pewnej hipotezy statystycznej w populacji na podstawie danych pochodzących z próby losowej
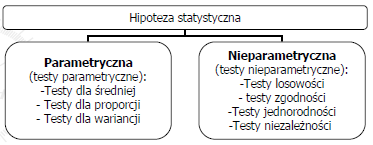
14 Testy parametryczne weryfikują hipotezy dotyczące wartości parametrów rozkładu badanej populacji (najczęściej średnie, wariancje, odsetki). W większości przypadków statystyki testowe obliczane są przy wykorzystaniu bezpośrednich danych pochodzących z próby, a ich rozkład zależy od rozkładu analizowanych zmiennych. Testy nieparametryczne służą do weryfikacji różnorakich hipotez, lecz nie są one bezpośrednio powiązane z parametrami rozkładu (bywają wyjątki). Dotyczą one raczej samej postaci rozkładu (kształtu), podobieństwa pomiędzy rozkładami, losowości. Testy te operują na danych przekształconych najczęściej rang, wobec czego rozkład statystyki z próby nie zależy bezpośrednio od rozkładu danych.
15 wartości badanych zmiennych: średnia wzrost mężczyzn w wieku 30 lat wynosi 179 cm różnicy między grupami osobników w zakresie rozpatrywanej cechy: lek A skuteczniej zwiększa krzepliwość krwi niż lek B zależności między badanymi cechami: istnieje silna zależność pomiędzy ilością wypalanych papierosów a zachorowalnością na nowotwór płuc porównania rozkładu zmiennych: zmienna masa ciała ma rozkład normalny
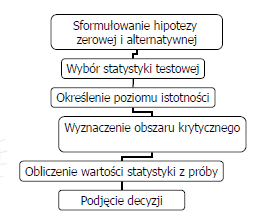
16 Weryfikacja hipotez statystycznych polega na zastosowaniu określonego schematu postępowania zwanego testem statystycznym, który rozstrzyga, przy jakich wynikach z próby sprawdzoną hipotezę należy odrzucić, a przy jakich nie ma podstaw do jej odrzucenia.
17 parametryczne (służą do weryfikacji hipotez parametrycznych) i testy nieparametryczne weryfikacja hipotez nieparametrycznych. Hipoteza, która podlega sprawdzeniu zwana jest hipotezą zerową (H0). Konkurencyjną dla niej hipotezą jest hipoteza alternatywna (HA). Hipoteza zerowa - ma najczęściej miejsce wówczas, gdy domniemamy, że pomiędzy rozpatrywanymi parametrami lub rozkładami dwóch czy też kilku populacji nie ma różnic.
18
19 1. Sformułowanie tezy rzeczowej i ustaleniu hipotez H 0 i H a ; 2. Wyboru właściwej funkcji testowej (statystyki z próby); 3. Przyjęciu stosownego poziomu istotności ; 4. Odczytaniu wartości krytycznych w tablicach dystrybuanty właściwego rozkładu i ustaleniu obszaru krytycznego; 5. Odrzuceniu hipotezy zerowej na korzyść hipotezy alternatywnej, gdy funkcja testowa obliczona z próby znajduje się w obszarze krytycznym i nie odrzucenie jej, gdy funkcja testowa jest poza obszarem krytycznym.
20 Najpierw trzeba dysponowad modelami, które mogą opisywad badaną zbiorowośd. Takim bardzo ogólnym modelem, który może byd zastosowany do opisu zachowania się cechy w populacji, jest tzw. Zmienna losowa. Jest to wielkośd, która w wyniku doświadczenia przyjmuje różne wartości, przy czym przed doświadczeniem nie jesteśmy w stanie określid z absolutną pewnością, jaka wartośd właśnie się pojawi (zrealizuje). Co najwyżej potrafimy określid zbiór możliwych wartości, jakie mogą pojawid się, oraz odpowiadające im prawdopodobieostwa.
21 Prawdopodobieostwa te muszą sumowad się do jedności. Funkcja, która opisuje sposób przyporządkowania prawdopodobieostw poszczególnym wartościom zmiennej losowej, nazywa się rozkładem prawdopodobieostwa. Zmienne losowe dzielą się na skokowe i ciągłe. Rozkład prawdopodobieostwa może byd przedstawiany przy użyciu różnych funkcji. Najbardziej uniwersalna jest dystrybuanta, która podaje prawdopodobieostwo tego, że zmienna losowa przyjmie wartości mniejszą od zadanej liczby. Przy zmiennych skokowych korzystamy z funkcji rozkładu prawdopodobieostwa, która przyporządkowuje prawdopodobieostwo konkretnym wartościom.
22 Przy zmiennych losowych ciągłych stosujemy funkcję gęstości prawdopodobieostwa. Pokazuje ona jak prawdopodobieostwo rozkłada się w przedziale zmienności danej zmiennej losowej. Wśród rozkładów prawdopodobieostwa zmiennej ciągłej najczęściej mówi się o rozkładzie normalnym. Funkcja gęstości tego rozkładu ma kształt dzwonowaty, symetryczny. Większośd zjawisk kształtowanych przez naturę czy zakłóceo czysto losowych rozkłada się wg tej funkcji. Dodatkowo wiele zmiennych losowych po prostych przekształceniach da się sprowadzid do rozkładu normalnego.
23 f(x) b a f ( x) dx a b x
24 f(x) krzywa Gaussa f x x e 2 2 Parametry: wartość oczekiwana odchylenie standardowe x
25 f(t) Rozklad t-studenta 30 st. swob. 3 st. swob. 1 st. swob normalny t
26 f(chi^2) Rozklad chi-kwadrat 10 st. swob. 3 st. swob. 1 st. swob normalny chi^2
27 f(x) eksponencjalny log-normalny logistyczny normalny x
28 Zmienna losowa może byd również opisana przy pomocy pewnych charakterystyk liczbowych, z których wiele jest jednocześnie parametrami funkcji opisujących rozkład prawdopodobieostwa. Najczęściej mowa tu o miarach położenia (wartośd przeciętna, modalna, mediana, kwantyle) oraz miarach zmienności (wariancja, odchylenie standardowe, współczynnik zmienności, odchylenie dwiartkowe). Kształt rozkładu jest charakteryzowany przez miary asymetrii, spłaszczenia i koncentracji.
29 O wiele częściej jest jednak tak, ze nie znamy typu rozkładu ani wartości parametrów. I wtedy przychodzi z pomocą wspomniane wcześniej wnioskowanie statystyczne. Wnioskujemy o zbiorowości (populacji) na podstawie próby. Poprawnośd wnioskowania zależy przede wszystkim od tego, czy próba dobrze reprezentuje analizowaną populację, czy struktura próby jest jak najbardziej zbliżona do struktury populacji. Reprezentatywnośd próby jest zapewniona, gdy próba jest losowa. Jednak losowośd nie zawsze jest oczywista.
30 Obejmuje 2 grupy metod: Estymację oraz Weryfikację hipotez statystycznych.
31 Szacowanie, odgadywanie rozkładu lub wartości parametrów w populacji na podstawie próby. Estymacja rozkładu to estymacja nieparametryczna. Najprostszą metodą jest tu obliczanie częstości oraz rysowanie histogramu, który pozwala wstępnie określid typ rozkładu. Estymacja parametryczna wykorzystuje pewne charakterystyki liczbowe wyliczane z próby.
32 Ponieważ próba jest losowa, to i estymator jest zmienną losową posiadającą własny rozkład prawdopodobieostwa. Wymaga się, aby estymatory były zgodne (czyli w miarę wzrostu liczebności próby coraz precyzyjniej odgadywały szacowany parametr), nieobciążone (średnio trafiające w nieznany parametr), efektywne (zapewniające mały błąd estymacji) oraz odporne (mało wrażliwe na błędy w danych).
33 Jeżeli przyjmujemy, ze nieznana wartośd parametru jest równa ocenie (wartości estymatora) otrzymanej w próbie, to mamy do czynienia z estymacją punktową. Można też wykorzystywad informacje o rozkładzie estymatora i konstruowad tzw. Przedziały ufności, czyli przedziały liczbowe, o których z dużą ufnością (zazwyczaj 95 %) możemy powiedzied, że zawierają w sobie nieznaną, szukaną wartośd parametru.

34 Pozwala przy pomocy testów statystycznych (TS) zweryfikować hipotezę (sąd) o rozkładzie lub parametrze populacji. TS to procedura pozwalająca odrzucić badaną hipotezę z małym ryzykiem popełnienia błędu polegającego na odrzuceniu hipotezy prawdziwej. Ryzyko to mierzone jest tzw. poziomem istotności, który przez większość badaczy przyjmowany jest na poziomie 0,05.
35 Przy korzystaniu z TS badacz musi sformułowad hipotezę zerową (rozkład jest określonego typu, parametr jest równy konkretnej liczbie, parametry w dwóch populacjach są równe, itp.) oraz hipotezę alternatywą.
36 Niezmiernie ważnym jest wybór właściwego testu statystycznego i sprawdzenie założeo przez niego wymaganych. Testy parametryczne wymagają, aby rozkład badanej cechy był określonego typu (zazwyczaj normalny), a testy nieparametryczne wolne są odtakich założeo. Dawniej oceniało się to poprzez odczytywanie z tablic tzw. Wartości krytycznych i porównywanie z nimi empirycznej wartości statystyki testowej. Obecnie wszystkie statystyczne pakiety komputerowe podają wartośd p, która jest prawdopodobieostwem otrzymania wyniku bardziej przeczącą hipotezie zerowej niż ten rezultat, który właśnie otrzymaliśmy.
37 Hipotezę zerową należy odrzucid, gdy wartośd p jest mniejsza od przyjętego poziomu istotności. Jeżeli natomiast wartośd p jest większa od poziomu istotności, nie oznacza to udowodnienia prawdziwości hipotezy zerowej. Mówimy wtedy po prostu, ze nie ma podstaw do odrzucenia tej hipotezy, a więc potwierdzamy hipotezę alternatywną i tylko tyle, i aż tyle.
38 Przy weryfikacji hipotez statystycznych można podjąd poprawną decyzję lub można popełnid jeden z dwóch błędów: błąd I rodzaju polegający na odrzuceniu testowanej hipotezy H0, gdy jest ona prawdziwa; błąd II rodzaju polegający na przyjęciu hipotezy H0, gdy jest ona fałszywa (tzn. prawdziwa jest hipoteza alternatywna HA).
39 Decyzja Przyjąć H0 Odrzucić H0 H0 jest prawdziwa Decyzja poprawna Decyzja błędna (błąd I rodzaju) H0 jest fałszywa Decyzja błędna (błąd II rodzaju) Decyzja poprawna
40 Aby skonstruowad test statystyczny pozwalający weryfikowad hipotezę H0, należy określid następujące elementy: wybrad statystykę testową stosownie do treści postawionej hipotezy H0; ustalid dopuszczalne prawdopodobieostwo błędu pierwszego rodzaju, tzn. ustalid poziom istotności testu; określid hipotezę alternatywną; wyznaczyd zbiór krytyczny tak, aby przy danym poziomie istotności zminimalizowad prawdopodobieostwo błędu drugiego rodzaju.
41 Testem istotności nazywamy test, którego celem jest jedynie zweryfikowanie jednej wysuniętej hipotezy pod kątem jej fałszywości z pominięciem innych hipotez. Testy istotności uwzględniają jedynie prawdopodobieostwo popełnienia błędu I rodzaju. Należy pamiętad, że nieodrzucenie weryfikowanej hipotezy H0 nie oznacza jej przyjęcia.
 - wówczas stosuje się najczęściej testy parametryczne; porównanie")
42 W badaniach medycznych najczęściej spotykanym problemem statystycznym jest porównanie dwóch populacji pod względem jednej cechy lub dwóch cech. Metody takich porównao można podzielid na dwie grupy: porównywanie pewnych parametrów populacji (średnie, odchylenia standardowe) - wówczas stosuje się najczęściej testy parametryczne; porównanie pewnych cech, które nie są parametrami (np. kształt rozkładu) - w takich przypadkach zwykle stosuje się testy nieparametryczne.
43 Wprawdzie parametr jest bardziej poszukiwaną i ważniejszą charakterystyką, zarówno populacji, jak i pojedynczego człowieka, jednakże jego brak nie zmusza do rezygnacji z badao statystycznych. W medycynie i biologii bardzo często przeprowadza się badania porównujące wartości dwóch lub kilku średnich.
44 Należy zapamiętać, że w procesie weryfikacji hipotez przez błąd nie rozumie się typowego błędu obliczeniowego, lecz tzw. błąd wnioskowania Wyróżnia się dwa podstawowe rodzaje błędów w testach statystycznych Błąd I rodzaju (poziom istotności α) polega na tym, że odrzucamy badaną hipotezę H0 podczas gdy jest ona prawdziwa Błąd II rodzaju (β) polega na tym, że przyjmujemy badaną hipotezę H0 podczas gdy jest ona fałszywa Pożądane jest aby oba te błędy były jak najmniejsze, jednakże w praktyce jest tak, że obniżenie jednego z nich powoduje wzrost drugiego Jedynym wyjściem jest minimalizowanie błędu II rodzaju, przy ustalonej wielkości błędu I rodzaju (poziomu istotności).
45 Przez pojęcie mocy testu rozumie się prawdopodobieństwo odrzucenia hipotezy zerowej kiedy jest ona fałszywa. Innymi słowy moc testu = 1 β (1-prawdop.błędu II rodzaju). Test statystyczny może być mocny gdy w większości przypadków jest w stanie odrzucić fałszywą H0. Test statystyczny może być słaby gdy istnieje duże prawdopodobieństwo przyjęcia H0 pomimo jej fałszywości. W badaniach klinicznych, badaniach nad nowymi lekami, etc. minimalna moc testu powinna wynosić 0,8.
46
47 Testy normalności rozkładu są specyficznymi testami badającymi zgodność danego rozkładu z rozkładem normalnym Rozkład normalny jest najczęściej wykorzystywanym rozkładem w statystyce, gdyż wiele cech ma właśnie rozkład zbliżony do niego Ma specyficzne własności (m.in.): Jest symetryczny (obserwacje rozkładają się równomiernie wokół średniej: średnia=mediana=dominanta) 68,27 % wyników jest w przedziale (m -σ, m + σ) 95,45 % wyników jest w przedziale (m -2σ, m +2σ) 99,73 % wyników jest w przedziale (m -3σ, m + 3σ) Założenie o normalności rozkładu wymagane jest często w przypadku testów parametrycznych
48
49 Wśród licznych rozkładów ciągłych największe znaczenie w statystyce posiada rozkład normalny. W przyrodzie bowiem istnieje silna tendencja rozkładania zbiorów wokół średnich w pewien charakterystyczny sposób, zwany rozkładem normalnym (Gaussa). Kształt krzywej rozkładu normalnego (krzywa o kształcie dzwonu, biegnąca do nieskończoności w obu kierunkach) zależy od 2 parametrów: oraz µ.
50 Parametr µ to wartość średnia populacji, względem której rozkład jest symetryczny. Parametr to odchylenie standardowe stanowiące miarę rozrzutu, zmienność wokół średniej µ. Najczęściej nie znamy prawdziwej wartości µ, lecz oceniamy (szacujemy ją) na podstawie średniej obliczonej z próby x Podobnie jeśli nie znamy, estymujemy odchylenie populacji na podstawie odchylenia w próbie (s). W rozkładzie normalnym: średnia, mediana i moda są sobie równe.
51 O zmiennej losowej X mówimy, że ma rozkład normalny, jeżeli jej gęstość prawdopodobieństwa określa równanie: f 1 x 1 ( i ) ( x ) e 2 i 2 2 f(x i )- gęstość = (stosunek obwodu koła do średnicy e=2,71828 x i - wartości z przedziału (-,+ )
52 Równanie to pozwala m.in. określić pole obszaru pod krzywą pomiędzy dwoma punktami (x1 i x2) na osi poziomej, jeżeli znane są: średnia i odchylenie standardowe. Pole to równa się prawdopodobieństwu (P) tego, że zmienna losowa X posiadająca taki rozkład ciągły przyjmie wartość określonego przedziału w granicach wyznaczonych przez te wartości (x1,x2). Powierzchnia ta równa się: P( x 1 X x 2 1 ) 2 x 2 x 1 e ( x ) dx
53 f(x) b a f ( x) dx a b x
54 Można dokonać transformacji dowolnego rozkładu normalnego do standaryzowanego rozkładu normalnego ze średnią równą 0 i odchyleniem standardowym 1. Standaryzacji dokonujemy odejmując (x) od wartości x i i dzieląc różnicę przez (s). Jeżeli zmienna X ma rozkład normalny ze średnią µ i wariancją 2, wówczas zmienna ma również rozkład normalny ze średnią 0 i odchyleniem standardowym 1. X
55
56
57
58 Prawdopodobieństwo pod krzywą normalną odpowiadające całkowitej liczbie obserwacji (N) jest równe jedności. Przyjmując krzywą standaryzowaną, gdzie N=100, możemy w określaniu powierzchni pod krzywą operować procentami.
59 ok. 68% wszystkich wartości zmiennej odbiega od średniej oczekiwanej nie bardziej niż o jedno odchylenie standardowe, ok. 95 % wszystkich wartości nie bardziej niż o dwa odchylenia, a w zasadzie wszystkie wartości (99.8%) zmiennej nie odbiegają od oczekiwanej wartości średniej bardziej niż o trzy odchylenia standardowe. Tak więc w przedziale (µ-,µ) i (µ,µ+ ) znajduje się ~34% pomiarów (razem ~68%). Na powierzchnię środkową krzywej (µ ) przypada 2/3 całej powierzchni, tj. 68% (p=0,68). W przedziale (µ-2,µ) i (µ,µ+ 2 ) powierzchnia pod krzywą stanowi 47,72% (razem ~95,5%). Poza dwoma odchyleniami od średniej pozostaje po ~2,25% pola pod krzywą normalną.
60 Kiedy cecha X ma rozkład normalny, wspomniane 95,5% odpowiada prawdopodobieństwu, że 95,5% wyników losowo wybranych zawiera się w przedziale o końcach µ 2. W granicach µ 3 powinno się znaleźć 99,74% obserwacji.
61 Wynik z przedziału x 1s i x 2s Oraz x 1s i x 2s nazywamy w medycynie wynikiem klinicznodiagnostycznie ostrzegawczym. Wynik pomiędzy x 2s i x 3s jest diagnostycznie wątpliwy. Wynik powyżej wartości x 3s lub poniżej x 3s wskazuje na stan patologiczny.

62
63 Zmiana wartości średniej powoduje przesunięcie krzywej rozkładu w lewo lub w prawo, podczas gdy zmiana odchylenia std. Zmienia wysokość lub szerokość krzywej, a więc wpływa na kształt rozkładu. Parametrami kształtu rozkładu są: skośność i kurtoza
64 Charakteryzuje odchylenie rozkładu od symetrii. Jeśli wartość standaryzowana skośności po standaryzacji jest wyraźnie różna od zera, wówczas dany rozkład jest asymetryczny, odstaje od charakterystyki rozkładu normalnego, który jest doskonale symetryczny. Dla rozkładu lewoskośnego: 1 < 0 Dla rozkładu prawoskośnego: 1 > 0 ( K 3 ) ( x i N ) 3 K 1 3 3
65 Dla rozkładu normalnego: średnia, mediana i moda są identyczne Dla rozkładu lewoskośnego: średnia < mediana < moda Dla rozkładu prawoskośnego: średnia > mediana > moda
66 A normalny B dwumodalny C prawoskośny D - lewoskośny

67 Wyliczana jest z wzoru: ( K ) ( x i ) 4 4 N K Po standaryzacji: Kurtoza mierzy spiczastość rozkładu.
68 Jeżeli kurtoza jest wyraźnie < 0, wówczas rozkład jest albo bardziej spłaszczony od normalnego albo bardziej wysmukły. Dla rozkładu normalnego kurtoza wynosi dokładnie 0. Wartości 2 > 0 charakteryzują rozkład leptokurtyczny (wysmukły). Wartości 2 < 0 charakteryzują rozkład platykurtyczny (spłaszczony). a) Rozkład mezokurtyczny (normalny) b) Złożony rozkład 2 populacji, dla których średnie są w przybliżeniu równe, ale wariancje jednej są sporo większe od drugiej. c) Rozkład leptokurtyczny (wysmukły) d) Rozkład platykurtyczny (spłaszczony) szczegolny przypadek dwumodalnego.
69 Najczęściej świadczy o występowaniu dwóch niezależnych subpopulacji normalnych o zbliżonych średnich i różnych wariancjach.
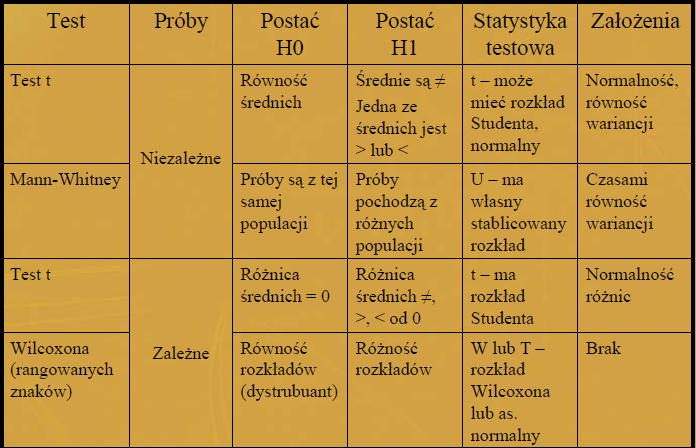
70 Jest szczególnym przypadkiem rozkładu dwumodalnego, czyli takiego, który posiada 2 maksima. Taki objaw wskazuje, że próba nie jest jednorodna i jej obserwacje pochodzą z 2 różnych populacji, z których każda ma rozkład normalny. Takie próby powinno się rozdzielić i osobno analizować każdą.
71 Wnioski statystyczne, u podstawy których leży pewność wynosząca co najmniej 95% (p<0,05), nazywamy istotnymi. Kiedy podstawą odrzucenia hipotezy jest prawdopodobieństwo błędu mniejsze niż 0,1% (np. przy =0,001), to wnioski takie określamy jako wysoce (bardzo) istotne (p<0,001). Kiedy otrzymane w wyniku doświadczenia wartości zmiennej X mieszczą się w przedziale ustalonym na poziomie istotności, wówczas hipotezę zerową odrzucamy. Z tego powodu przedział ten nazywa się przedziałem krytycznym.
72 Gdy mamy standardowy rozkład normalny N(0,1) to każda wartość cechy x i oddalona jest od średniej 0 o określoną liczbę odchyleń standardowych (z). Prawdopodobieństwo (skumulowane częstości powierzchnia) dla wartości z mniejszych niż z=-1.96 wynosi 0,025 (2,5%). Dla wartości mniejszych niż z=-2.58 to prawdopodobieństwo wynosi 0,005, a prawdopodobieństwu 0,0005 odpowiada wartość z =
73 Pobierając losowo z rozkładu normalnego pojedynczy element, mamy szansę 2.5% ze pierwszym wylosowanym elementem będzie liczba mniejsza od wartości średniej o więcej niż 1.96 odchyleń standardowych oraz szansę 2.5% ze będzie to wartość większa od wartości średniej o więcej niż 1.96 odchyleń standardowych. Kiedy dla pojedynczego pomiaru a wartość z >1.96, czyli z< lub z>1.96 to hipotezę H0, iż nasz pojedynczy pomiar pobrano losowo z rozkładu normalnego odrzucamy (p<0,05, wnioskowanie ze słusznością większą od 95%). Kiedy dla pojedynczego pomiaru a wartość z >2.58 to hipotezę H0 odrzucamy z jeszcze większą pewnością, tzn. na poziomie istotności =0,01 (p<0,01, wnioskowanie ze słusznością większą od 99%). Kiedy dla pojedynczego pomiaru a wartość z >3.29 to hipotezę H0 odrzucamy z jeszcze większą pewnością, tzn. na poziomie istotności =0,001 (p<0,001, wnioskowanie ze słusznością większą od 99,9%).
74 W wybranej losowo grupie studentów oznaczono zawartość hemoglobiny Hb we krwi (g/100ml), otrzymując następujące dane: 14.0, 15.4, 13.7, 15.8, 15.2, Zweryfikować hipotezę, że średnia zawartość Hb w populacji mającej rozkład normalny, o nieznanej wariancji równa się 15g/100ml, do alternatywnej. Rozwiązanie: inaczej testujemy, czy losową próbę o liczności n=6, pobrano z populacji o rozkładzie normalnym ze średnią µ=15g/100 ml. Ponieważ nie znamy wariancji z populacji 2 i mamy małą próbę a więc do testowania powyższej hipotezy użyć możemy tylko rozkładu t. Wobec tego: H0:µ=15 Ha:µ 15 Obliczone wartości średniej, odchylenia standardowego, i wariancji wynoszą odpowiednio Średnia µ=14.97, wariancja S2 = 0,804, odchylenie standardowe s=0, t Wyliczamy wartość doświadczalną t d : d 0, Dla testu dwustronnego przy =0,05 odczytana wartość tabelaryczna t t /2 (n-1)=t(0,025;5) = 2,57. Ponieważ td=0,08 < t t < 2.57, nie ma podstaw do odrzucenia hipotezy zerowej, że µ = 15g/100 ml (p>0,05).
75
76
77 rozkład populacji nie różni się istotnie od rozkładu normalnego, wartość oczekiwana (średnia) badanej cechy nie różni się istotnie od 20, wartości oczekiwane (średnie) badanej cechy w dwóch grupach nie różnią się istotnie, nie ma istotnej zależności pomiędzy dwoma badanymi cechami.
78 rozkład populacji różni się istotnie od rozkładu normalnego, Wartość oczekiwana (średnia) badanej cechy jest istotnie większa od 20, wartości oczekiwane (średnie) badanej cechy w dwóch grupach różnią się istotnie, istnieje istotna zależność pomiędzy dwoma badanymi cechami.
79
80 1. Próby niezależne - obserwacje w poszczególnych grupach dokonywane są na różnych obiektach. 2. Próby zależne - obserwacje dokonywane są dwukrotnie na tych samych obiektach.
81 1. Porównanie poziomów parametrów medycznych dla dwóch grup sprowadza się z reguły do porównania przeciętnych poziomów zmiennych lub też porównania rozkładów analizowanego parametru 2. Należy ustalić czy próby są niezależne czy też zależne 3. Czy znane są rozkłady cech w populacji, w próbkach? 4. Jeżeli spełnione są wszystkie założenia (głównie normalność, ewentualnie równość wariancji, liczebność prób) należy wykonać test parametryczny: Test t dla prób niezależnych Test t dla prób zależnych (założenie: rozkład różnic ma być zbliżony do normalnego) 5. W przypadku naruszenia jakiegokolwiek z założeń (np. jedna z grup ma rozkład cechy istotnie różny od normalnego lub jest bardzo mała) wówczas wykonuje się test nieparametryczny: Dla prób niezależnych: test Manna-Whitneya-Wilcoxona Dla prób zależnych: test kolejności par Wilcoxona (rangowanych znaków) Alternatywa: normalizacja danych, wykonywanie testów parametrycznych na danych rangowanych.
82
83 Liczba grup do porównania nie powinna być za duża (teoretycznie kilkanaście, praktycznie najlepiej kilka). Jeżeli porównanie ma być reprezentatywne to próby powinny być raczej liczne oraz mieć zbliżone liczności (nie powinna występować sytuacja, w której np. dwie grupy liczą po 40 obserwacji, a trzecie 8). Większość medycznych porównań wielu grup dotyczy poziomów analizowanych parametrów medycznych (głównie średnie). W przypadku zmiennych jakościowych porównuje się po prostu odsetki w kilku grupach (k>2). Najczęściej mamy też do czynienia z analizą jednoczynnikową (jeden czynnik grupujący/efekt/zmienna zależna). W przypadku wielu czynników można badać interakcje pomiędzy czynnikami (jeżeli jest to uzasadnione).
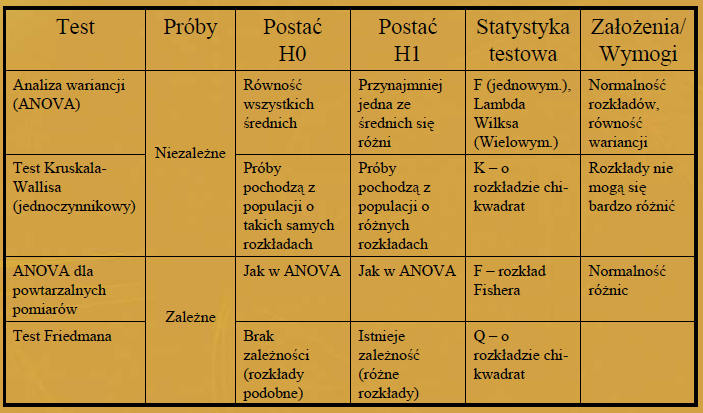
84
85 Wcześniejsze procedury testowe wykrywają tylko czy istnieje różnica w poziomach/rozkładach przynajmniej jednej z grup, tj. czy przynajmniej jedna z grup się różni od pozostałych. Nie podają ile grup się różni i które z nich. W celu wykrycia różnic wykonuje się tzw. testy porównań wielokrotnych (testy post-hoc/testy po fakcie). Testy post-hoc pokazują, które z grup mogą różnić się istotnie pomiędzy sobą. Ich konstrukcja jest podobna do testu t dla dwóch grup, jednakże co ważne biorą one pod uwagę poprawkę na ilość wykonywanych porównań na tych samych danych ( korekcja poziomu p). Nieuzasadnione jest stosowanie testu t lub Manna- Whitneya dla porównań wielokrotnych (są wyjątki).

86

87
88
89 p wartość jest najmniejszym poziomem istotności testu, przy którym odrzucamy hipotezę zerową, zatem jeżeli p wartość, to odrzucamy H0, jeżeli p wartość>, to nie ma podstaw do odrzucenia H0.
90 prawostronny obszar krytyczny: P0(T T(x)), lewostronny obszar krytyczny: P0(T T(x)), dwustronny obszar krytyczny: 2 min{ P0(T T(x)), P0(T T(x)) }.
91 Wynikiem testowania hipotez statystycznych jest jedna z dwóch decyzji: 1. "odrzucamy hipotezę zerową" tzn. Stwierdzamy występowanie istotnych statystycznie różnic (zależności), na poziomie istotności, 2. "nie ma podstaw do odrzucenia hipotezy zerowej", tzn. stwierdzamy brak istotnych statystycznie różnic (zależności), na poziomie istotności.
92 Testy najmocniejsze testy minimalizujące prawdopodobieństwo popełnienia błędu II rodzaju przy ustalonym z góry poziomie prawdopodobieństwa popełnienia błędu I rodzaju. Moc testu M (w) prawdopodobieństwo odrzucenia fałszywej hipotezy H 0 i przyjęcia w to miejsce prawdziwej hipotezy alternatywnej: M w P W w/ H n 1 Związek między mocą testu i prawdopodobieństwem błędu II rodzaju: w 1 M w
93 Służą one do weryfikacji hipotez parametrycznych, odnoszących się do parametrów rozkładu badanej cechy w populacji generalnej. Najczęściej weryfikują sądy o takich parametrach populacji jak średnia arytmetyczna, wskaźnik struktury i wariancja. Testy te konstruowane są przy założeniu znajomości postaci dystrybuanty w populacji generalnej. Biorąc pod uwagę zakres ich zastosowań, testy te można podzielić na dwie grupy: 1. Testy parametryczne służące do weryfikacji własności populacji jednowymiarowych, 2. Testy parametryczne służące do porównania własności dwóch populacji.
94 Testy parametryczne służące do weryfikacji własności populacji jednowymiarowych, a wśród nich wyróżnia się: testy dla średniej test dla proporcji (wskaźnika struktury) test dla wariancji W testach tych oceny parametrów uzyskane z próby losowej są porównywane z hipotetycznymi wielkościami parametrów, traktowanymi jako pewien wzorzec. Testy parametryczne służące do porównania własności dwóch populacji, do których należą: test dla dwóch średnich test dla dwóch proporcji test dla dwóch wariancji Testy te porównują oceny parametrów, uzyskane z dwóch prób losowych.
95 Służą do weryfikacji różnorodnych hipotez, dotyczących m.in. zgodności rozkładu cechy w populacji z określonym rozkładem teoretycznym, zgodności rozkładów w dwóch populacjach, a także losowości doboru próby. Biorąc pod uwagę zakres ich zastosowań, testy te można podzielić na dwie grupy: 1. Testy nieparametryczne służące do porównania własności dwóch populacji, 2. Testy nieparametryczne służące do weryfikacji własności populacji jednowymiarowych
 weryfikuje hipotezę o losowym pochodzeniu obserwacji badanej cechy w")
96 test zgodności chi-kwadrat test zgodności λ Kołmogorowa test normalności Shapiro-Wilka test serii Dwa pierwsze testy zgodności oceniają zgodność rozkładu empirycznego z teoretycznym, natomiast test serii (losowości) weryfikuje hipotezę o losowym pochodzeniu obserwacji badanej cechy w próbie.
97 test Kołmogorowa-Smirnowa test jednorodności chi-kwadrat test mediany test serii test znaków Budowa tych testów sprowadza się do oceny zgodności dwóch rozkładów empirycznych, otrzymanych z prób niezależnych (test Kołmogorowa- Smirnowa, jednorodności chi-kwadrat, test mediany, test serii), a także zgodności rozkładów w próbach połączonych (test znaków).
98 Test na wykrycie wyniku obarczonego błędem grubym. Przed wykonaniem testu zbiór wyników eksperymentalnych (próbka statystyczna) zostaje uszeregowany według wzrastających wartości. Błędem grubym może być obarczona największa lub najmniejsza wartość wyniku w próbce. Dla tych wyników obliczane są odpowiednio parametry T max i T min. Parametr o większej wartości porównywany jest następnie z parametrem krytycznym testu Grubbsa, odpowiadającym rozmiarowi próbki statystycznej i wybranemu poziomowi ufności. Wartość krytyczna statystyki tego testu obliczana jest na podstawie paramtetru t rozkładu Studenta dla zadanego poziomu ufności i liczby stopni swobody (n - 2, n - liczba pomiarów w serii). Jeśli wartość eksperymentalna jest większa od wartości krytycznej, wówczas podejrzany wynik obarczony jest błędem grubym i można go odrzucić z zadanym poziomem ufności.
99 Dla sprawdzenia, czy dwa pomiary różnią się między sobą stosujemy: test znaków lub test Wilcoxona. Pierwszy z nich wybieramy, gdy dane mają rozkład normalny, drugi, gdy nie. Oba te testy dotyczą zmiennych zależnych, najczęściej są to pomiary pochodzące od tych samych osób. Hipoteza zerowa mówi, że wyniki obu próbek są jednakowe.
100 Test znaków oparty jest na znakach różnic pomiędzy parami wyników. Liczba plusów i minusów jest zliczana i porównywana z wartością teoretyczną umieszczoną w odpowiednich tabelach. Tracimy informację niesioną przez liczbowe wartości różnic.
101 Test kolejności par Wilcoxona uwzględnia zarówno znak różnic, ich wielkość, jak i kolejność. Po uporządkowaniu różnic w sposób rosnący są im przypisywane rangi, a następnie sumowane osobno rangi różnic dodatnich i ujemnych. Ich suma po porównaniu z tabelą wartości teoretycznych decyduje o przyjęciu lub nie hipotezy zerowej.
102 1. Pierwszą rzeczą, jaką musimy zrobić, jest sprawdzenie, czy dane mają rozkład normalny, wykonując testy normalności rozkładu. 2. Następnie wybieramy Analiza / Testy nieparameryczne / Dwie próby zależne... i w oknie dialogowym zaznaczamy Wilcoxon lub Test znaków oraz przerzucamy zmienne, które chcemy poddać analizie.
103 Wiele testów parametrycznych wymaga, by dane pochodziły z rozkładu zbliżonego do normalnego. Dlatego testy badające normalność rozkładów są tak istotne. W testach tych zawsze przyjmuje się H 0 - rozkład zmiennej jest normalny. Odrzucenie H 0 jest wiec równoznaczne z przyjęciem hipotezy, że rozkład zmiennej nie jest normalny. Brak podstaw do odrzucenia nie oznacza przyjęcia hipotezy o normalności rozkładu. Musimy to jeszcze sprawdzić i w tym celu sporządzane są wykresy prawdopodobieństwo - prawdopodobieństwo.
104 W pakiecie SPSS testy badające normalność rozkładu dostępne są w Analiza / Opis statystyczny / Eksploracja i tam wybierając opcję Wykresy... należy zaznaczyć Wykresy normalności z testami. SPSS dla małych próbek wykonuje dwa testy: Test Kołmogorowa - Smirnowa z poprawką Lilleforsa, która jest obliczana, gdy nie znamy średniej lub odchylenia standardowego całej populacji. Test Shapiro - Wilka - najbardziej polecany, ale może dawać błędne wyniki dla próbek większych niż 2 tys. Jeżeli komputer wskaże istotność mniejszą niż zadeklarowany poziom istotności, to hipotezę o normalności rozkładu odrzucamy, jeżeli większą - nie mamy podstaw do odrzucenia. Należy wówczas ocenić normalność na podstawie wykresów prawdopodobieństwo - prawdopodobieństwo.
105 Test chi-kwadrat (χ 2 ) - każdy test statystyczny, w którym statystyka testowa ma rozkład chikwadrat, jeśli teoretyczna zależność jest prawdziwa. Test chi kwadrat służy sprawdzaniu hipotez. Innymi słowy wartość testu oceniana jest przy pomocy rozkładu chi kwadrat. Test najczęściej wykorzystywany w praktyce. Możemy go wykorzystywać do badania zgodności zarówno cech mierzalnych, jak i niemierzalnych. Jest to jedyny test do badania zgodności cech niemierzalnych.
106 W ogólności zachodzi: gdzie: O i - wartość mierzona, E i - odpowiadająca wartość teoretyczna (oczekiwana), wynikająca z hipotezy σ i - odchylenie standardowe, n - liczba pomiarów. Zliczenia W szczególności gdy wartościami są zliczenia wtedy ich odchylenie standardowe wynosi i równanie przechodzi na: Uwagi: przyjmuje się że wartość E i powinna być większa lub równa 5 (spotyka się też 10 - nie ma ścisłego wyprowadzenia, minimalnej wielkości). czasem z tego powodu przy pomiarach wartości dyskretnych łączy się te wartości w jeden przedział (patrz przykład). przy pomiarze wartości ciągłej wartość teoretyczna to całka z rozkładu prawdopodobieństwa po odpowiednim przedziale z którego zliczane były wyniki.
107 test nieparametryczny używany do porównywania rozkładów jednowymiarowych cech statystycznych. Istnieją dwie główne wersje tego testu dla jednej próby i dla dwóch prób. Test dla jednej próby (zwany też testem zgodności λ Kołmogorowa) sprawdza, czy rozkład w populacji dla pewnej zmiennej losowej, różni się od założonego rozkładu teoretycznego, gdy znana jest jedynie pewna skończona liczba obserwacji tej zmiennej (próba statystyczna). Często wykorzystywany jest on w celu sprawdzenia, czy zmienna ma rozkład normalny. Dla celów testowania normalności zostały dokonane w teście drobne usprawnienia, znane jako test Lillieforsa. Istnieje też wersja testu dla dwóch prób, pozwalająca na porównanie rozkładów dwóch zmiennych losowych. Jego zaletą jest wrażliwość zarówno na różnice w położeniu, jak i w kształcie dystrybuanty empirycznej porównywanych próbek.
108 Testy dla średniej to grupa testów statystycznych, służących do wnioskowania o wartości średniej w populacji, z której pochodzi próba losowa. Hipotezę zerową i alternatywną oznaczamy w następujący sposób: H 0 : μ = μ 0 Zakłada ona, że nieznana średnia w populacji μ jest równa średniej hipotetycznej μ 0 H 1 : μ μ 0 lub H 1 : μ > μ 0 lub H 1 : μ < μ 0 Jest ona zaprzeczeniem H 0, występuje w trzech wersjach w zależności od sformułowania badanego problemu. Sprawdzianem hipotezy jest statystyka testowa, która jest funkcją wyników próby losowej. Postać funkcji testowej (tzw. statystyki) zależy od trzech okoliczności: rozkładu cechy w populacji znajomości wartości odchylenia standardowego w populacji liczebności próby Biorąc pod uwagę powyższe okoliczności, założoną przez nas hipotezę możemy sprawdzić za pomocą trzech testów:
109 Jeżeli populacja ma rozkład normalny N(μ,σ) o nieznanej średniej μ i znanym odchyleniu standardowym σ, natomiast liczebność próby n jest dowolna, wtedy statystyka ma postać: gdzie: m - średnia z próby Jeżeli H 0 jest prawdziwa, to statystyka rozkład asymptotycznie normalny. testowa Z ma Wartość statystyki, którą obliczymy korzystając z powyższego wzoru, oznaczamy jako z. Następnie porównujemy ją z wartością krytyczną testu z α, którą możemy odczytać z tablic standaryzowanego rozkładu normalnego, uwzględniając poziom istotności α. Decyzję o odrzuceniu H 0 podejmujemy, jeżeli wartość statystyki znajduje się w obszarze krytycznym. Jeżeli natomiast wartość ta znajdzie się poza obszarem krytycznym, nie ma wtedy podstaw do odrzucenia H 0.
110 Znane odchylenie Jeżeli populacja ma rozkład normalny N(μ,σ) o nieznanej średniej μ i znanym odchyleniu standardowym σ, natomiast liczebność próby n jest dowolna, wtedy statystyka ma postać: gdzie: m - średnia z próby Jeżeli H 0 jest prawdziwa, to statystyka testowa Z ma rozkład asymptotycznie normalny. Wartość statystyki, którą obliczymy korzystając z powyższego wzoru, oznaczamy jako z. Następnie porównujemy ją z wartością krytyczną testu z α, którą możemy odczytać z tablic standaryzowanego rozkładu normalnego, uwzględniając poziom istotności α. Decyzję o odrzuceniu H 0 podejmujemy, jeżeli wartość statystyki znajduje się w obszarze krytycznym. Jeżeli natomiast wartość ta znajdzie się poza obszarem krytycznym, nie ma wtedy podstaw do odrzucenia H 0.
111 Jeżeli rozkład populacji jest normalny N(μ,σ), o nieznanej średniej μ i nieznanym odchyleniu standardowym σ, natomiast liczebność próby jest mała (np. n<30), wtedy statystyka ma postać: Jeżeli H 0 jest prawdziwa, to statystyka testowa ma rozkład t-studenta o liczbie stopni swobody ν = n-1. Wartość statystyki, którą obliczymy korzystając z powyższego wzoru, oznaczamy jako t. Następnie porównujemy ją z wartością krytyczną testu t α, którą odczytujemy z tablic rozkładu t-studenta przy założonym poziomie istotności α oraz liczbie stopni swobody ν = n- 1. Decyzję o odrzuceniu H 0 podejmujemy, jeżeli wartość statystyki znajduje się w obszarze krytycznym. Jeżeli natomiast wartość ta znajdzie się poza obszarem krytycznym, nie ma wtedy podstaw do odrzucenia H 0.
112
113
114
115 Obszar krytyczny to obszar odrzucenia hipotezy zerowej. Położenie (postać obszaru krytycznego) wyznacza postać hipotezy alternatywnej. Wielkość obszaru krytycznego jest równa poziomowi istotności.
116
117 Z tablic rozkładu statystyki odczytujemy wartość krytyczną (graniczną wartość obszaru krytycznego oddzielającą go od reszty rozkładu)
118 Obliczamy wartość statystyki z próby w
119
120
 4.")
121 1. Test chi-kwadrat 2. Test Kołmogorowa - Smirnowa dla jednej próbki 3. Test Kuipera (opracowana przez Kuipera jest modyfikacją testu Kołmogorowa Smirnowa poprawiającą jego właściwości w krańcowych obszarach rozkładu) 4. Test Cramera-von Mises a - Statystyka Cramera-von Mises a porównuje obserwacje w próbce (traktowane jako próba losowa) z próbą losową pobraną z hipotetycznego rozkładu. 5. Test Watsona - Jest to kolejna modyfikowana statystyka Cramera-von Mises a. 6. Test Andersona-Darlinga - Ocena stopnia dopasowania dystrybuanty testowanego rozkładu z obliczoną na podstawie próby dystrybuantą empiryczną. Test ten może być stosowany tylko dla kompletnych danych (bez w jakikolwiek sposób brakujących obserwacji).
122 1. Test normalności Lillieforsa. Jeżeli parametry rozkładu hipotetycznego są nieznane, to jak już wspomniano test K- S może dawać błędne wyniki. Jednak w przypadku rozkładu normalnego można w takiej sytuacji zastosować tę samą statystykę zmodyfikowaną przez Lilleforsa. Dlatego też test ten stosowany jest najczęściej do weryfikacji normalności rozkładu. 2. Test normalności Shapiro-Wilka. W odróżnieniu od wcześniej opisanych testów zgodności w tym przypadku wzrost wartości statystyki oznacza większą zgodność wyników z rozkładem normalnym. Jednak poziom prawdopodobieństwa odpowiadający tej statystyce testowej podawany jest w programach statystycznych w ten sam sposób, jak w innych testach tzn., jeżeli wartość spadnie poniżej ustalonego poziomu istotności testu, to hipotezę o zgodności z rozkładem normalnym odrzucamy.
123 1. Kołmogorowa-Smirnowa (tzw. test K-S2), 2. Mann-Whitneya, 3. Walda Wolfowitza, 4. test znaków, 5. Wilkoxona. Testy K-S2, Mann-Whitneya, Walda Wolfowitza stosowane są w przypadku zmiennych niezależnych. Pozostałe dwa testy są alternatywą testu t dla zmiennych zależnych (parowanych). Test Kołmogorowa-Smirnowa (dla dwóch próbek) Test Kołmogorowa-Smirnowa (K-S2) pozwala określić, czy dwie próbki (niezależne) pochodzą z populacji o takim samym rozkładzie. W odróżnieniu od testów parametrycznych test K-S2 jest nie tylko czuły na położenie środka rozkładu czy jego szerokość, ale również na kształt rozkładu.
124 Do najczęściej stosowanych testów statystycznych operujących na jednym zbiorze danych należą: test t-studenta dla jednej średniej (sprawdzający, czy wyniki pochodzą z populacji o danej średniej), test Shapiro-Wilka na rozkład normalny (sprawdzający, czy próba pochodzi z populacji o rozkładzie normalnym) oraz test z (sprawdzający, czy próba pochodzi z populacji o rozkładzie normalnym, gdy znane jest _ tej populacji). Przy wnioskowaniu dla jednej średniej, w razie stwierdzenia rozkładu innego niż normalny, zamiast testu t stosuje sie test rang Wilcoxona.

125 Rozważmy np. wyniki np. 6 analiz chemicznych test posłuży do sprawdzenia, czy mogą pochodzić z populacji o średniej równej 100:
126 > dane = c(96.19,98.07,103.53,99.81,101.60,103.44) > shapiro.test(dane) # czy rozkład jest normalny? Shapiro-Wilk normality test data: dane W = , p-value = > t.test(dane,mu=100) # tak, a zatem sprawdzamy testem Studenta One Sample t-test data: dane t = , df = 5, p-value = alternative hypothesis: true mean is not equal to percent confidence interval: sample estimates: mean of x wilcox.test(dane,mu=100) # tak byśmy sprawdzali, gdyby nie był Wilcoxon signed rank test data: dane V = 11, p-value = 1 alternative hypothesis: true mu is not equal to 100
127 przedział ufności można bardzo prosto obliczyć ręcznie dla dowolnego. Załóżmy, że = 3, zas = 0.05: > ci = qnorm(1-0.05/2) > ci [1] > s = 3/sqrt(length(dane)) > s [1] > mean(dane) + c(-s*ci,s*ci) [1]
128 Podstawowymi testami dla dwóch zbiorów danych są: test F-Snedecora na jednorodność wariancji (sprawdzający, czy wariancje obu prób różnią się istotnie między sobą), test t-studenta dla dwóch średnich (porównujący, czy próby pochodzą z tej samej populacji; wykonywany w razie jednorodnej wariancji) oraz test U-Manna-Whitneya, będący odmianą testu Wilcoxona, służący do stwierdzenia równości średnich w razie uprzedniego wykrycia niejednorodności wariancji.
129 Do poprzedniego zbioru danych dodamy drugi zbiór dane2 i przeprowadzimy te testy: > dane2 = c(99.70,99.79,101.14,99.32,99.27,101.29) > var.test(dane,dane2) # czy jest jednorodność wariancji? F test to compare two variances data: dane and dane2 F = , num df = 5, denom df = 5, p-value = alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: sample estimates: ratio of variances > wilcox.test(dane,dane2) # jednak różnice wariancji, wiec test Wilcoxona Wilcoxon rank sum test data: dane and dane2 W = 22, p-value = # dane sie istotnie nie różnią alternative hypothesis: true mu is not equal to 0 > t.test(dane,dane2) # a tak byśmy zrobili, gdyby różnic nie było Welch Two Sample t-test data: dane and dane2 t = , df = 5.913, p-value = alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: sample estimates: mean of x mean of y
130 > dane2 = c(99.70,99.79,101.14,99.32,99.27,101.29) > var.test(dane,dane2) # czy jest jednorodność wariancji? F test to compare two variances data: dane and dane2 F = , num df = 5, denom df = 5, p-value = alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: sample estimates: ratio of variances
131 > wilcox.test(dane,dane2) # jednak różnice wariancji, wiec test Wilcoxona Wilcoxon rank sum test data: dane and dane2 W = 22, p-value = # dane sie istotnie nie różnią alternative hypothesis: true mu is not equal to 0 > t.test(dane,dane2) # a tak byśmy zrobili, gdyby różnic nie było Welch Two Sample t-test data: dane and dane2 t = , df = 5.913, p-value = alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: sample estimates: mean of x mean of y
132 Jeśli zachodzi potrzeba wykonania testu z innym niż 0.05, korzystamy z opcji conf.level każdego testu (standardowo jest to 0.95). W funkcji t.test można również ustawić paired=true i w ten sposób policzyć test dla danych powiązanych parami. Warto też zwrócić uwagę na parametr conf.int w funkcji wilcox.test, który pozwala na obliczenie przedziału ufności dla mediany.
133 W przypadku analizy statystycznej większej grupy danych, np. wyników analizy chemicznej wykonanej trzema metodami, konieczne jest umieszczenie wszystkich danych w jednej ramce (dataframe).
134 Dołóżmy jeszcze kolejne 6 wyników do wektora dane3 i umieśćmy wszystko w ramce: > dane3 = c(91.50,96.74,108.17,94.22,99.18,105.48) > danex = data.frame(wyniki=c(dane,dane2,dane3),metoda=rep(1:3,each=6)) > danex wyniki metoda
135 Na tak wykonanej ramce możemy wykonać już poszczególne testy. Do porównania jednorodności wariancji służy tutaj test Bartletta, który jest rozwinięciem testu F-Snedecora na większą liczbę prób. W razie stwierdzenia istotnych różnic w wariancji badamy istotne różnice pomiędzy grupami wyników testem Kruskala-Wallisa. Jeśli nie ma podstaw do odrzucenia hipotezy o jednorodności wariancji, rekomendowanym testem jest najprostszy wariant ANOVA.
136 > bartlett.test(wyniki ~ metoda,danex) # czy jest niejednorodność? Bartlett test for homogeneity of variances data: wyniki by metoda Bartlett s K-squared = , df = 2, p-value = > kruskal.test(wyniki~metoda,danex) # jest, wiec Kruskar-Wallis Kruskal-Wallis rank sum test data: wyniki by metoda Kruskal-Wallis chi-squared = , df = 2, p-value = > anova(aov(wyniki~metoda,danex)) # a tak, gdyby nie było Analysis of Variance Table Response: wyniki Df Sum Sq Mean Sq F value Pr(>F) metoda Residuals
137 Załóżmy, ze oznaczyliśmy w 4 próbkach zawartość jakiejś substancji, każda próbkę badaliśmy 4 metodami (w sumie 16 wyników). Stosując dwuczynnikowy test ANOVA można sprawdzić, czy wyniki różnią sie istotnie miedzy próbkami i miedzy metodami. W tym celu znów tworzymy ramkę zawierającą wyniki oraz odpowiadające im próbki i metody:
138 > dane wynik probka metoda
139 > anova(aov(wynik ~ probka + metoda,dane)) # test bez interakcji Analysis of Variance Table Response: wynik Df Sum Sq Mean Sq F value Pr(>F) probka metoda Residuals > anova(aov(wynik ~ probka * metoda,dane)) # test z~interakcjami Analysis of Variance Table Response: wynik Df Sum Sq Mean Sq F value Pr(>F) probka metoda probka:metoda Residuals Podany powyżej test z interakcjami nie ma sensu merytorycznego w tym przypadku, pokazano go tylko przykładowo
140 Załóżmy np. ze wśród 300 ankietowanych osób odpowiedz tak padła w 30 przypadkach. Daje to 10% ankietowanych. Czy można powiedzieć, że wśród ogółu populacji tylko 7% tak odpowiada? Jaki jest przedział ufności dla tego prawdopodobieństwa? > prop.test(30,300,p=0.07) 1-sample proportions test with continuity correction data: 30 out of 300, null probability 0.07 X-squared = , df = 1, p-value = alternative hypothesis: true p is not equal to percent confidence interval: sample estimates: p 0.1
141 Jak widać, przedział ufności zawiera sie w granicy %, zatem 7% zawiera sie w nim (p nieznacznie większe niż 0.05). Innym przykładem jest porównanie kilku takich wyników. Załóżmy, ze w innej 200-osobowej grupie odpowiedz padła u 25 osób, a w trzeciej, 500-osobowej, u 40 osób. Czy próby te pochodzą z tej samej populacji? > prop.test(c(30,25,40),c(300,200,500)) 3-sample test for equality of proportions without continuity correction data: c(30, 25, 40) out of c(300, 200, 500) X-squared = , df = 2, p-value = alternative hypothesis: two.sided sample estimates: prop 1 prop 2 prop Jak widać, test nie wykazał istotnych różnic. Jeśli chcielibyśmy wprowadzić do testu poprawkę Yates a, dodajemy parametr cont=true.
142 Test 2 na zgodność rozkładu jest wbudowany w R pod funkcja chisq.test. W przypadku wnioskowania zgodności rozkładu pierwszy wektor zawiera dane, a drugi prawdopodobieństwa ich wystąpienia w testowanym rozkładzie. Załóżmy, że w wyniku 60 rzutów kostka otrzymaliśmy następujące ilości poszczególnych wyników 1 6: 6,12,9,11,15,7. Czy różnice pomiędzy wynikami świadczą o tym, ze kostka jest nieprawidłowo skonstruowana, czy są przypadkowe? > kostka=c(6,12,9,11,15,7) > pr=rep(1/6,6) # prawdopodobieństwo każdego rzutu wynosi 1/6 > pr [1] > chisq.test(kostka,p=pr) Chi-squared test for given probabilities data: kostka X-squared = 5.6, df = 5, p-value =
143 Jeśli parametrem funkcji chisq.test jest ramka, funkcja przeprowadza test 2 na niezależność. Załóżmy, ze w grupie pacjentów badanych nowym lekiem 19 pozostało bez poprawy, 41 odnotowało wyraźną poprawę, 60 osób całkowicie wyzdrowiało. W grupie kontrolnej (leczonej dotychczasowymi lekami) wartości te wynosiły odpowiednio 46,19,15. Czy nowy lek faktycznie jest lepszy? Jeśli tak, dane powinny być zależne, i tak tez jest: > lek=c(19,41,60) > ctl=c(46,19,15) > chisq.test(cbind(lek,ctl)) # cbind tworzy ramke! Pearson s Chi-squared test data: cbind(lek, ctl) X-squared = , df = 2, p-value = 2.192e-09
144 Pakiet R posiada wbudowane algorytmy pozwalające na obliczanie gęstości, dystrybuanty i kwantyli najczęściej stosowanych rozkładów. Może również pracować jako precyzyjny generator liczb losowych. Standardowo dostępne są następujące rozkłady: beta, binom, cauchy, chisq, exp, f, gamma, geom, hyper, lnorm, logis, nbinom, norm, pois, t, unif, weibull, wilcox. Poprzedzając nazwę rozkładu literą d uzyskujemy funkcję gęstości rozkładu. Analogicznie poprzedzając nazwę literą p uzyskujemy wartości dystrybuanty. Funkcja kwantylowa (poprzedzona q) podaje taki kwantyl, który po lewej stronie wykresu gęstości zawiera określone prawdopodobieństwo. Generator liczb losowych dostępny jest przy poprzedzeniu nazwy litera r. Funkcje te pozwalają na traktowanie pakietu R jako zestawu bardzo dokładnych tablic statystycznych.
145 > dnorm(0) # gęstość rozkładu normalnego w zerze [1] > pnorm(1)-pnorm(-1) # ile wartości mieści sie w N(0,1) w przedziale (0,1)? [1] > qt(0.995,5) # wartość krytyczna t-studenta dla 99% i 5 stopni swobody [1] > qchisq(0.01,5) # wartość krytyczna chi-kwadrat dla 5 st. swobody i 99% [1] > dpois(0,0.1) # wartość prawdop. Poissona dla lambda 0.1 i n=0 [1] > qf(0.99,5,6) # wartość krytyczna testu F dla n1=5, n2=6 [1]
146 Kilku słów wymaga wartość (nie 0.99) w wywołaniu funkcji rozkładu t-studenta. Rozkład ten jest zwykle stosowany w kontekście dwustronnym, dlatego obszar krytyczny dzielimy równomiernie na obu końcach rozkładu. 99% ufności oznacza, ze krytyczny 1% jest podzielony na 2 końce i zawiera sie w przedziałach (0, 0.05) oraz (0.995, 1). Wartość tablicowa jest kwantylem obliczonym dla takiego właśnie prawdopodobieństwa. Analogicznie np. dla 95% będzie to 0.975, a dla 99.9%
147 Korzystając z funkcji generatora losowego można generować dowolne ciągi danych do późniejszej analizy. Wygenerujmy przykładowy zestaw 30 liczb o średniej 50 i odchyleniu standardowym 5, posiadających rozkład normalny: > rnorm(30,50,5) [1] [9] [17] [25]
148 Oczywiście funkcja ta wygeneruje za każdym razem całkowicie inne wartości, dlatego też prowadząc analizy należy je zapamiętać w zmiennej, a potem używać tej zmiennej w dalszych operacjach. Warto przy okazji wspomnieć o funkcji sample, generującej wektor danych wylosowanych z innego wektora. Np. funkcja sample(1:6,10,replace=t) symuluje 10 rzutów kostka (losowanie ze zbioru 1:6), a dane mogą sie powtarzać. Jeśli nie jest podana liczba losowanych danych (np. sample(1:6)), funkcja generuje losowa permutacje wektora podanego jako parametr.

149 cudowne lekarstwo na wolne rodniki
150

151
152
153
154
155

156
157
158
159
160
161

162
163
164
165 rozstęp zmiennej
166
167
168
169
170

171

172 sar/dane/coagulation.txt
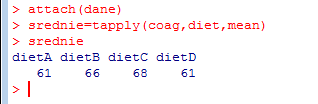
173
174

175
176
177
178 Szukamy: - obserwacji odstających, - skośności rozkładów (niesymetryczne skrzynki) - nierówności wariancji (nierówne wielkości skrzynek) Dla zbioru coagulation nieregularności na wykresie skrzynkowym wynikają raczej z malej liczby obserwacji.
179
180 Test równości wariancji w grupach (Używamy poziomu istotności 0.01, bo procedury związane z ANOVA są w miarę odporne na odstępstwo od założenia o równych wariancjach w grupach) # TEST BARTLETTA (nie jest najlepszy, bo nieodporny na odstępstwo od założenia o normalności rozkładu w grupach) bartlett.test(coag~diet)
181 TEST LEVENE'A (odporny na odstępstwo od założenia o normalności rozkładu w grupach) # Liczymy wartości bezwzględne rezyduów i używamy ich jako zmiennej odpowiedzi w analizie wariancji:
182 Na podstawie wyniku testu F stwierdzamy, ze istnieją różnice w średnich miedzy grupami
183 Zatem dieta jest poziomem odniesienia. średnia na poziomie dieta: 61 średnia na poziomie dietb: 61+5 średnia na poziomie dietc: 61+7 średnia na poziomie dietd: 61-0
184
185
186
187

188
Testy nieparametryczne
 Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testy nieparametryczne Testy nieparametryczne możemy stosować, gdy nie są spełnione założenia wymagane dla testów parametrycznych. Stosujemy je również, gdy dane można uporządkować według określonych kryteriów
Testowanie hipotez statystycznych. Wnioskowanie statystyczne
 Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Testowanie hipotez statystycznych Wnioskowanie statystyczne Hipoteza statystyczna to dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Hipotezy
Wnioskowanie statystyczne Weryfikacja hipotez. Statystyka
 Wnioskowanie statystyczne Weryfikacja hipotez Statystyka Co nazywamy hipotezą Każde stwierdzenie o parametrach rozkładu lub rozkładzie zmiennej losowej w populacji nazywać będziemy hipotezą statystyczną
Wnioskowanie statystyczne Weryfikacja hipotez Statystyka Co nazywamy hipotezą Każde stwierdzenie o parametrach rozkładu lub rozkładzie zmiennej losowej w populacji nazywać będziemy hipotezą statystyczną
Statystyka matematyczna dla leśników
 Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka matematyczna dla leśników Wydział Leśny Kierunek leśnictwo Studia Stacjonarne I Stopnia Rok akademicki 03/04 Wykład 5 Testy statystyczne Ogólne zasady testowania hipotez statystycznych, rodzaje
Statystyka. Rozkład prawdopodobieństwa Testowanie hipotez. Wykład III ( )
") Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Statystyka Rozkład prawdopodobieństwa Testowanie hipotez Wykład III (04.01.2016) Rozkład t-studenta Rozkład T jest rozkładem pomocniczym we wnioskowaniu statystycznym; stosuje się go wyznaczenia przedziału
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji
 Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Weryfikacja hipotez statystycznych, parametryczne testy istotności w populacji Dr Joanna Banaś Zakład Badań Systemowych Instytut Sztucznej Inteligencji i Metod Matematycznych Wydział Informatyki Politechniki
Błędy przy testowaniu hipotez statystycznych. Decyzja H 0 jest prawdziwa H 0 jest faszywa
 Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
Weryfikacja hipotez statystycznych Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o prawdziwości lub fałszywości którego wnioskuje się na podstawie
TESTY NIEPARAMETRYCZNE. 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa.
 TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
TESTY NIEPARAMETRYCZNE 1. Testy równości średnich bez założenia normalności rozkładu zmiennych: Manna-Whitney a i Kruskala-Wallisa. Standardowe testy równości średnich wymagają aby badane zmienne losowe
W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne.
 W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne. dr hab. Jerzy Nakielski Katedra Biofizyki i Morfogenezy Roślin Plan wykładu: 1. Etapy wnioskowania statystycznego 2. Hipotezy statystyczne,
W2. Zmienne losowe i ich rozkłady. Wnioskowanie statystyczne. dr hab. Jerzy Nakielski Katedra Biofizyki i Morfogenezy Roślin Plan wykładu: 1. Etapy wnioskowania statystycznego 2. Hipotezy statystyczne,
Zadania ze statystyki, cz.6
 Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
Zadania ze statystyki, cz.6 Zad.1 Proszę wskazać, jaką część pola pod krzywą normalną wyznaczają wartości Z rozkładu dystrybuanty rozkładu normalnego: - Z > 1,25 - Z > 2,23 - Z < -1,23 - Z > -1,16 - Z
Statystyka. #5 Testowanie hipotez statystycznych. Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik. rok akademicki 2016/ / 28
 Statystyka #5 Testowanie hipotez statystycznych Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2016/2017 1 / 28 Testowanie hipotez statystycznych 2 / 28 Testowanie hipotez statystycznych
Statystyka #5 Testowanie hipotez statystycznych Aneta Dzik-Walczak Małgorzata Kalbarczyk-Stęclik rok akademicki 2016/2017 1 / 28 Testowanie hipotez statystycznych 2 / 28 Testowanie hipotez statystycznych
RÓWNOWAŻNOŚĆ METOD BADAWCZYCH
 RÓWNOWAŻNOŚĆ METOD BADAWCZYCH Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska Równoważność metod??? 2 Zgodność wyników analitycznych otrzymanych z wykorzystaniem porównywanych
RÓWNOWAŻNOŚĆ METOD BADAWCZYCH Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska Równoważność metod??? 2 Zgodność wyników analitycznych otrzymanych z wykorzystaniem porównywanych
Statystyka matematyczna. Wykład IV. Weryfikacja hipotez statystycznych
 Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
Statystyka matematyczna. Wykład IV. e-mail:e.kozlovski@pollub.pl Spis treści 1 2 3 Definicja 1 Hipoteza statystyczna jest to przypuszczenie dotyczące rozkładu (wielkości parametru lub rodzaju) zmiennej
S t a t y s t y k a, część 3. Michał Żmihorski
 S t a t y s t y k a, część 3 Michał Żmihorski Porównanie średnich -test T Założenia: Zmienne ciągłe (masa, temperatura) Dwie grupy (populacje) Rozkład normalny* Równe wariancje (homoscedasticity) w grupach
S t a t y s t y k a, część 3 Michał Żmihorski Porównanie średnich -test T Założenia: Zmienne ciągłe (masa, temperatura) Dwie grupy (populacje) Rozkład normalny* Równe wariancje (homoscedasticity) w grupach
LABORATORIUM 3. Jeśli p α, to hipotezę zerową odrzucamy Jeśli p > α, to nie mamy podstaw do odrzucenia hipotezy zerowej
 LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
LABORATORIUM 3 Przygotowanie pliku (nazwy zmiennych, export plików.xlsx, selekcja przypadków); Graficzna prezentacja danych: Histogramy (skategoryzowane) i 3-wymiarowe; Wykresy ramka wąsy; Wykresy powierzchniowe;
Weryfikacja hipotez statystycznych
 Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Weryfikacja hipotez statystycznych Hipoteza Test statystyczny Poziom istotności Testy jednostronne i dwustronne Testowanie równości wariancji test F-Fishera Testowanie równości wartości średnich test t-studenta
Założenia do analizy wariancji. dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW
 Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
Założenia do analizy wariancji dr Anna Rajfura Kat. Doświadczalnictwa i Bioinformatyki SGGW anna_rajfura@sggw.pl Zagadnienia 1. Normalność rozkładu cechy Testy: chi-kwadrat zgodności, Shapiro-Wilka, Kołmogorowa-Smirnowa
STATYSTYKA I DOŚWIADCZALNICTWO. Wykład 2
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład Parametry przedziałowe rozkładów ciągłych określane na podstawie próby (przedziały ufności) Przedział ufności dla średniej s X t( α;n 1),X + t( α;n 1) n s n t (α;
STATYSTYKA I DOŚWIADCZALNICTWO Wykład Parametry przedziałowe rozkładów ciągłych określane na podstawie próby (przedziały ufności) Przedział ufności dla średniej s X t( α;n 1),X + t( α;n 1) n s n t (α;
Testowanie hipotez statystycznych
 Testowanie hipotez statystycznych Hipotezą statystyczną jest dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Prawdziwość tego przypuszczenia
Testowanie hipotez statystycznych Hipotezą statystyczną jest dowolne przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Prawdziwość tego przypuszczenia
Statystyczna analiza danych w programie STATISTICA (wykład 2) Dariusz Gozdowski
 Dariusz Gozdowski") Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
Statystyczna analiza danych w programie STATISTICA (wykład ) Dariusz Gozdowski Katedra Doświadczalnictwa i Bioinformatyki Wydział Rolnictwa i Biologii SGGW Weryfikacja (testowanie) hipotez statystycznych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
STATYSTYKA wykład 8. Wnioskowanie. Weryfikacja hipotez. Wanda Olech
 TATYTYKA wykład 8 Wnioskowanie Weryfikacja hipotez Wanda Olech Co nazywamy hipotezą Każde stwierdzenie o parametrach rozkładu lub rozkładzie zmiennej losowej w populacji nazywać będziemy hipotezą statystyczną
TATYTYKA wykład 8 Wnioskowanie Weryfikacja hipotez Wanda Olech Co nazywamy hipotezą Każde stwierdzenie o parametrach rozkładu lub rozkładzie zmiennej losowej w populacji nazywać będziemy hipotezą statystyczną
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 6 Metody sprawdzania założeń w analizie wariancji: -Sprawdzanie równości (jednorodności) wariancji testy: - Cochrana - Hartleya - Bartletta -Sprawdzanie zgodności
VI WYKŁAD STATYSTYKA. 9/04/2014 B8 sala 0.10B Godz. 15:15
 VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
VI WYKŁAD STATYSTYKA 9/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 6 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności, zasady
Testowanie hipotez statystycznych
 Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Agenda Instytut Matematyki Politechniki Łódzkiej 2 stycznia 2012 Agenda Agenda 1 Wprowadzenie Agenda 2 Hipoteza oraz błędy I i II rodzaju Hipoteza alternatywna Statystyka testowa Zbiór krytyczny Poziom
Wydział Matematyki. Testy zgodności. Wykład 03
 Wydział Matematyki Testy zgodności Wykład 03 Testy zgodności W testach zgodności badamy postać rozkładu teoretycznego zmiennej losowej skokowej lub ciągłej. Weryfikują one stawiane przez badaczy hipotezy
Wydział Matematyki Testy zgodności Wykład 03 Testy zgodności W testach zgodności badamy postać rozkładu teoretycznego zmiennej losowej skokowej lub ciągłej. Weryfikują one stawiane przez badaczy hipotezy
Wykład 3 Hipotezy statystyczne
 Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
Wykład 3 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu obserwowanej zmiennej losowej (cechy populacji generalnej) Hipoteza zerowa (H 0 ) jest hipoteza
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI
 LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
LABORATORIUM 8 WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI WERYFIKACJA HIPOTEZ Hipoteza statystyczna jakiekolwiek przypuszczenie dotyczące populacji generalnej- jej poszczególnych
Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 4
, sprawozdanie z laboratorium 4") Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 4 Konrad Miziński, nr albumu 233703 31 maja 2015 Zadanie 1 Wartości oczekiwane µ 1 i µ 2 oszacowano wg wzorów: { µ1 = 0.43925 µ = X
Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 4 Konrad Miziński, nr albumu 233703 31 maja 2015 Zadanie 1 Wartości oczekiwane µ 1 i µ 2 oszacowano wg wzorów: { µ1 = 0.43925 µ = X
Spis treści. Laboratorium III: Testy statystyczne. Inżynieria biomedyczna, I rok, semestr letni 2013/2014 Analiza danych pomiarowych
 1 Laboratorium III: Testy statystyczne Spis treści Laboratorium III: Testy statystyczne... 1 Wiadomości ogólne... 2 1. Krótkie przypomnienie wiadomości na temat testów statystycznych... 2 1.1. Weryfikacja
1 Laboratorium III: Testy statystyczne Spis treści Laboratorium III: Testy statystyczne... 1 Wiadomości ogólne... 2 1. Krótkie przypomnienie wiadomości na temat testów statystycznych... 2 1.1. Weryfikacja
ODRZUCANIE WYNIKÓW POJEDYNCZYCH POMIARÓW
 ODRZUCANIE WYNIKÓW OJEDYNCZYCH OMIARÓW W praktyce pomiarowej zdarzają się sytuacje gdy jeden z pomiarów odstaje od pozostałych. Jeżeli wykorzystamy fakt, że wyniki pomiarów są zmienną losową opisywaną
ODRZUCANIE WYNIKÓW OJEDYNCZYCH OMIARÓW W praktyce pomiarowej zdarzają się sytuacje gdy jeden z pomiarów odstaje od pozostałych. Jeżeli wykorzystamy fakt, że wyniki pomiarów są zmienną losową opisywaną
166 Wstęp do statystyki matematycznej
 166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
166 Wstęp do statystyki matematycznej Etap trzeci realizacji procesu analizy danych statystycznych w zasadzie powinien rozwiązać nasz zasadniczy problem związany z identyfikacją cechy populacji generalnej
Analizy wariancji ANOVA (analysis of variance)
") ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
ANOVA Analizy wariancji ANOVA (analysis of variance) jest to metoda równoczesnego badania istotności różnic między wieloma średnimi z prób pochodzących z wielu populacji (grup). Model jednoczynnikowy analiza
SIGMA KWADRAT. Weryfikacja hipotez statystycznych. Statystyka i demografia CZWARTY LUBELSKI KONKURS STATYSTYCZNO-DEMOGRAFICZNY
 SIGMA KWADRAT CZWARTY LUBELSKI KONKURS STATYSTYCZNO-DEMOGRAFICZNY Weryfikacja hipotez statystycznych Statystyka i demografia PROJEKT DOFINANSOWANY ZE ŚRODKÓW NARODOWEGO BANKU POLSKIEGO URZĄD STATYSTYCZNY
SIGMA KWADRAT CZWARTY LUBELSKI KONKURS STATYSTYCZNO-DEMOGRAFICZNY Weryfikacja hipotez statystycznych Statystyka i demografia PROJEKT DOFINANSOWANY ZE ŚRODKÓW NARODOWEGO BANKU POLSKIEGO URZĄD STATYSTYCZNY
Testowanie hipotez statystycznych.
 Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Statystyka Wykład 10 Wrocław, 22 grudnia 2011 Testowanie hipotez statystycznych Definicja. Hipotezą statystyczną nazywamy stwierdzenie dotyczące parametrów populacji. Definicja. Dwie komplementarne w problemie
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Wykład 9 Testy rangowe w problemie dwóch prób
 Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Wykład 9 Testy rangowe w problemie dwóch prób Wrocław, 18 kwietnia 2018 Test rangowy Testem rangowym nazywamy test, w którym statystyka testowa jest konstruowana w oparciu o rangi współrzędnych wektora
Idea. θ = θ 0, Hipoteza statystyczna Obszary krytyczne Błąd pierwszego i drugiego rodzaju p-wartość
 Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Idea Niech θ oznacza parametr modelu statystycznego. Dotychczasowe rozważania dotyczyły metod estymacji tego parametru. Teraz zamiast szacować nieznaną wartość parametru będziemy weryfikowali hipotezę
Wykład 10 (12.05.08). Testowanie hipotez w rodzinie rozkładów normalnych przypadek nieznanego odchylenia standardowego
. Testowanie hipotez w rodzinie rozkładów normalnych przypadek nieznanego odchylenia standardowego") Wykład 10 (12.05.08). Testowanie hipotez w rodzinie rozkładów normalnych przypadek nieznanego odchylenia standardowego Przykład Cena metra kwadratowego (w tys. zł) z dla 14 losowo wybranych mieszkań w
Wykład 10 (12.05.08). Testowanie hipotez w rodzinie rozkładów normalnych przypadek nieznanego odchylenia standardowego Przykład Cena metra kwadratowego (w tys. zł) z dla 14 losowo wybranych mieszkań w
Hipotezy statystyczne
 Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej
Hipotezy statystyczne Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej
Statystyka matematyczna. Wykład VI. Zesty zgodności
 Statystyka matematyczna. Wykład VI. e-mail:e.kozlovski@pollub.pl Spis treści 1 Testy zgodności 2 Test Shapiro-Wilka Test Kołmogorowa - Smirnowa Test Lillieforsa Test Jarque-Bera Testy zgodności Niech x
Statystyka matematyczna. Wykład VI. e-mail:e.kozlovski@pollub.pl Spis treści 1 Testy zgodności 2 Test Shapiro-Wilka Test Kołmogorowa - Smirnowa Test Lillieforsa Test Jarque-Bera Testy zgodności Niech x
WNIOSKOWANIE STATYSTYCZNE
 STATYSTYKA WNIOSKOWANIE STATYSTYCZNE ESTYMACJA oszacowanie z pewną dokładnością wartości opisującej rozkład badanej cechy statystycznej. WERYFIKACJA HIPOTEZ sprawdzanie słuszności przypuszczeń dotyczących
STATYSTYKA WNIOSKOWANIE STATYSTYCZNE ESTYMACJA oszacowanie z pewną dokładnością wartości opisującej rozkład badanej cechy statystycznej. WERYFIKACJA HIPOTEZ sprawdzanie słuszności przypuszczeń dotyczących
Hipotezy statystyczne
 Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej próbki losowej. Hipotezy
Hipotezą statystyczną nazywamy każde przypuszczenie dotyczące nieznanego rozkładu badanej cechy populacji, o którego prawdziwości lub fałszywości wnioskuje się na podstawie pobranej próbki losowej. Hipotezy
Rozkład zmiennej losowej Polega na przyporządkowaniu każdej wartości zmiennej losowej prawdopodobieństwo jej wystąpienia.
 Rozkład zmiennej losowej Polega na przyporządkowaniu każdej wartości zmiennej losowej prawdopodobieństwo jej wystąpienia. D A R I U S Z P I W C Z Y Ń S K I 2 2 ROZKŁAD ZMIENNEJ LOSOWEJ Polega na przyporządkowaniu
Rozkład zmiennej losowej Polega na przyporządkowaniu każdej wartości zmiennej losowej prawdopodobieństwo jej wystąpienia. D A R I U S Z P I W C Z Y Ń S K I 2 2 ROZKŁAD ZMIENNEJ LOSOWEJ Polega na przyporządkowaniu
Testowanie hipotez. Hipoteza prosta zawiera jeden element, np. H 0 : θ = 2, hipoteza złożona zawiera więcej niż jeden element, np. H 0 : θ > 4.
 Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Testowanie hipotez Niech X = (X 1... X n ) będzie próbą losową na przestrzeni X zaś P = {P θ θ Θ} rodziną rozkładów prawdopodobieństwa określonych na przestrzeni próby X. Definicja 1. Hipotezą zerową Θ
Zadania ze statystyki cz. 8 I rok socjologii. Zadanie 1.
 Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Zadania ze statystyki cz. 8 I rok socjologii Zadanie 1. W potocznej opinii pokutuje przekonanie, że lepsi z matematyki są chłopcy niż dziewczęta. Chcąc zweryfikować tę opinię, przeprowadzono badanie w
Przedmowa Wykaz symboli Litery alfabetu greckiego wykorzystywane w podręczniku Symbole wykorzystywane w zagadnieniach teorii
 SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
SPIS TREŚCI Przedmowa... 11 Wykaz symboli... 15 Litery alfabetu greckiego wykorzystywane w podręczniku... 15 Symbole wykorzystywane w zagadnieniach teorii mnogości (rachunku zbiorów)... 16 Symbole stosowane
Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych.
 Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Hipotezy i Testy statystyczne Każde
Statystyka i opracowanie danych- W 8 Wnioskowanie statystyczne. Testy statystyczne. Weryfikacja hipotez statystycznych. Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Hipotezy i Testy statystyczne Każde
Wnioskowanie statystyczne i weryfikacja hipotez statystycznych
 Wnioskowanie statystyczne i weryfikacja hipotez statystycznych Wnioskowanie statystyczne Wnioskowanie statystyczne obejmuje następujące czynności: Sformułowanie hipotezy zerowej i hipotezy alternatywnej.
Wnioskowanie statystyczne i weryfikacja hipotez statystycznych Wnioskowanie statystyczne Wnioskowanie statystyczne obejmuje następujące czynności: Sformułowanie hipotezy zerowej i hipotezy alternatywnej.
Wprowadzenie do analizy korelacji i regresji
 Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Statystyka dla jakości produktów i usług Six sigma i inne strategie Wprowadzenie do analizy korelacji i regresji StatSoft Polska Wybrane zagadnienia analizy korelacji Przy analizie zjawisk i procesów stanowiących
Wykład 5 Problem dwóch prób - testowanie hipotez dla równości średnich
 Wykład 5 Problem dwóch prób - testowanie hipotez dla równości średnich Magdalena Frąszczak Wrocław, 22.03.2017r Problem Behrensa Fishera Niech X = (X 1, X 2,..., X n ) oznacza próbę z rozkładu normalnego
Wykład 5 Problem dwóch prób - testowanie hipotez dla równości średnich Magdalena Frąszczak Wrocław, 22.03.2017r Problem Behrensa Fishera Niech X = (X 1, X 2,..., X n ) oznacza próbę z rozkładu normalnego
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory
 Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Statystyka i opracowanie danych Podstawy wnioskowania statystycznego. Prawo wielkich liczb. Centralne twierdzenie graniczne. Estymacja i estymatory Dr Anna ADRIAN Paw B5, pok 407 adrian@tempus.metal.agh.edu.pl
Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 3
, sprawozdanie z laboratorium 3") Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 3 Konrad Miziński, nr albumu 233703 26 maja 2015 Zadanie 1 Wartość krytyczna c, niezbędna wyliczenia mocy testu (1 β) wyznaczono za
Modele i wnioskowanie statystyczne (MWS), sprawozdanie z laboratorium 3 Konrad Miziński, nr albumu 233703 26 maja 2015 Zadanie 1 Wartość krytyczna c, niezbędna wyliczenia mocy testu (1 β) wyznaczono za
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski
 Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Statystyka od podstaw Janina Jóźwiak, Jarosław Podgórski Książka jest nowoczesnym podręcznikiem przeznaczonym dla studentów uczelni i wydziałów ekonomicznych. Wykład podzielono na cztery części. W pierwszej
Rozkłady statystyk z próby
 Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
Rozkłady statystyk z próby Rozkłady statystyk z próby Przypuśćmy, że wykonujemy serię doświadczeń polegających na 4 krotnym rzucie symetryczną kostką do gry, obserwując liczbę wyrzuconych oczek Nr kolejny
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4
 STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
STATYSTYKA I DOŚWIADCZALNICTWO Wykład 4 Inne układy doświadczalne 1) Układ losowanych bloków Stosujemy, gdy podejrzewamy, że może występować systematyczna zmienność między powtórzeniami np. - zmienność
Weryfikacja hipotez statystycznych. KG (CC) Statystyka 26 V / 1
 Statystyka 26 V / 1") Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Weryfikacja hipotez statystycznych KG (CC) Statystyka 26 V 2009 1 / 1 Sformułowanie problemu Weryfikacja hipotez statystycznych jest drugą (po estymacji) metodą uogólniania wyników uzyskanych w próbie
Zawartość. Zawartość
 Opr. dr inż. Grzegorz Biesok. Wer. 2.05 2011 Zawartość Zawartość 1. Rozkład normalny... 3 2. Rozkład normalny standardowy... 5 3. Obliczanie prawdopodobieństw dla zmiennych o rozkładzie norm. z parametrami
Opr. dr inż. Grzegorz Biesok. Wer. 2.05 2011 Zawartość Zawartość 1. Rozkład normalny... 3 2. Rozkład normalny standardowy... 5 3. Obliczanie prawdopodobieństw dla zmiennych o rozkładzie norm. z parametrami
ANALIZA STATYSTYCZNA WYNIKÓW BADAŃ
 ANALIZA STATYSTYCZNA WYNIKÓW BADAŃ Dopasowanie rozkładów Dopasowanie rozkładów- ogólny cel Porównanie średnich dwóch zmiennych 2 zmienne posiadają rozkład normalny -> test parametryczny (t- studenta) 2
ANALIZA STATYSTYCZNA WYNIKÓW BADAŃ Dopasowanie rozkładów Dopasowanie rozkładów- ogólny cel Porównanie średnich dwóch zmiennych 2 zmienne posiadają rozkład normalny -> test parametryczny (t- studenta) 2
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część
 zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część") Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Populacja generalna (zbiorowość generalna) zbiór obejmujący wszystkie elementy będące przedmiotem badań Próba (podzbiór zbiorowości generalnej) część populacji, którą podaje się badaniu statystycznemu
Przykład 1. (A. Łomnicki)
") Plan wykładu: 1. Wariancje wewnątrz grup i między grupami do czego prowadzi ich ocena 2. Rozkład F 3. Analiza wariancji jako metoda badań założenia, etapy postępowania 4. Dwie klasyfikacje a dwa modele
Plan wykładu: 1. Wariancje wewnątrz grup i między grupami do czego prowadzi ich ocena 2. Rozkład F 3. Analiza wariancji jako metoda badań założenia, etapy postępowania 4. Dwie klasyfikacje a dwa modele
P: Czy studiujący i niestudiujący preferują inne sklepy internetowe?
 2 Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia czy pomiędzy zmiennymi istnieje związek/zależność. Stosujemy go w sytuacji, kiedy zmienna zależna mierzona jest na skali
2 Test niezależności chi-kwadrat stosuje się (między innymi) w celu sprawdzenia czy pomiędzy zmiennymi istnieje związek/zależność. Stosujemy go w sytuacji, kiedy zmienna zależna mierzona jest na skali
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej
 Pojęcie losowej próby prostej") 7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
7. Estymacja parametrów w modelu normalnym(14.04.2008) Pojęcie losowej próby prostej Definicja 1 n-elementowa losowa próba prosta nazywamy ciag n niezależnych zmiennych losowych o jednakowych rozkładach
Wykład 9 Wnioskowanie o średnich
 Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Wykład 9 Wnioskowanie o średnich Rozkład t (Studenta) Wnioskowanie dla jednej populacji: Test i przedziały ufności dla jednej próby Test i przedziały ufności dla par Porównanie dwóch populacji: Test i
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności. dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl
 Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka w pracy badawczej nauczyciela Wykład 4: Analiza współzależności dr inż. Walery Susłow walery.suslow@ie.tu.koszalin.pl Statystyczna teoria korelacji i regresji (1) Jest to dział statystyki zajmujący
Statystyka matematyczna Testowanie hipotez i estymacja parametrów. Wrocław, r
 Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Statystyka matematyczna Testowanie hipotez i estymacja parametrów Wrocław, 18.03.2016r Plan wykładu: 1. Testowanie hipotez 2. Etapy testowania hipotez 3. Błędy 4. Testowanie wielokrotne 5. Estymacja parametrów
Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona;
 LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
LABORATORIUM 4 Testowanie hipotez dla dwóch zmiennych zależnych. Moc testu. Minimalna liczność próby; Regresja prosta; Korelacja Pearsona; dwie zmienne zależne mierzalne małe próby duże próby rozkład normalny
Zad. 4 Należy określić rodzaj testu (jedno czy dwustronny) oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:
 oraz wartości krytyczne z lub t dla określonych hipotez i ich poziomów istotności:") Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
Zadania ze statystyki cz. 7. Zad.1 Z populacji wyłoniono próbę wielkości 64 jednostek. Średnia arytmetyczna wartość cechy wyniosła 110, zaś odchylenie standardowe 16. Należy wyznaczyć przedział ufności
weryfikacja hipotez dotyczących parametrów populacji (średnia, wariancja)
") PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
PODSTAWY STATYSTYKI. Teoria prawdopodobieństwa i elementy kombinatoryki. Zmienne losowe i ich rozkłady 3. Populacje i próby danych, estymacja parametrów 4. Testowanie hipotez 5. Testy parametryczne (na
VII WYKŁAD STATYSTYKA. 30/04/2014 B8 sala 0.10B Godz. 15:15
 VII WYKŁAD STATYSTYKA 30/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 7 (c.d) WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności,
VII WYKŁAD STATYSTYKA 30/04/2014 B8 sala 0.10B Godz. 15:15 WYKŁAD 7 (c.d) WERYFIKACJA HIPOTEZ STATYSTYCZNYCH PARAMETRYCZNE TESTY ISTOTNOŚCI Weryfikacja hipotez ( błędy I i II rodzaju, poziom istotności,
Testy dla dwóch prób w rodzinie rozkładów normalnych
 Testy dla dwóch prób w rodzinie rozkładów normalnych dr Mariusz Grządziel Wykład 12; 18 maja 2009 Przykład Rozważamy dane wygenerowane losowo; ( podobne do danych z przykładu 7.2 z książki A. Łomnickiego)
Testy dla dwóch prób w rodzinie rozkładów normalnych dr Mariusz Grządziel Wykład 12; 18 maja 2009 Przykład Rozważamy dane wygenerowane losowo; ( podobne do danych z przykładu 7.2 z książki A. Łomnickiego)
Wykład 12 ( ): Testy dla dwóch prób w rodzinie rozkładów normalnych
: Testy dla dwóch prób w rodzinie rozkładów normalnych") Wykład 12 (21.05.07): Testy dla dwóch prób w rodzinie rozkładów normalnych Przykład Rozważamy dane wygenerowane losowo; ( podobne do danych z przykładu 7.2 z książki A. Łomnickiego) n 1 = 9 poletek w dąbrowie,
Wykład 12 (21.05.07): Testy dla dwóch prób w rodzinie rozkładów normalnych Przykład Rozważamy dane wygenerowane losowo; ( podobne do danych z przykładu 7.2 z książki A. Łomnickiego) n 1 = 9 poletek w dąbrowie,
Doświadczalnictwo leśne. Wydział Leśny SGGW Studia II stopnia
 Doświadczalnictwo leśne Wydział Leśny SGGW Studia II stopnia Metody nieparametryczne Do tej pory omawialiśmy metody odpowiednie do opracowywania danych ilościowych, mierzalnych W kaŝdym przypadku zakładaliśmy
Doświadczalnictwo leśne Wydział Leśny SGGW Studia II stopnia Metody nieparametryczne Do tej pory omawialiśmy metody odpowiednie do opracowywania danych ilościowych, mierzalnych W kaŝdym przypadku zakładaliśmy
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki
 Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
Tablica Wzorów Rachunek Prawdopodobieństwa i Statystyki Spis treści I. Wzory ogólne... 2 1. Średnia arytmetyczna:... 2 2. Rozstęp:... 2 3. Kwantyle:... 2 4. Wariancja:... 2 5. Odchylenie standardowe:...
b) Niech: - wśród trzech wylosowanych opakowań jest co najwyżej jedno o dawce 15 mg. Wówczas:
 Niech: - wśród trzech wylosowanych opakowań jest co najwyżej jedno o dawce 15 mg. Wówczas:") ROZWIĄZANIA I ODPOWIEDZI Zadanie A1. Można założyć, że przy losowaniu trzech kul jednocześnie kolejność ich wylosowania nie jest istotna. A więc: Ω = 20 3. a) Niech: - wśród trzech wylosowanych opakowań
ROZWIĄZANIA I ODPOWIEDZI Zadanie A1. Można założyć, że przy losowaniu trzech kul jednocześnie kolejność ich wylosowania nie jest istotna. A więc: Ω = 20 3. a) Niech: - wśród trzech wylosowanych opakowań
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych
 WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
WYKŁADY ZE STATYSTYKI MATEMATYCZNEJ wykład 9 i 10 - Weryfikacja hipotez statystycznych Agata Boratyńska Agata Boratyńska Statystyka matematyczna, wykład 9 i 10 1 / 30 TESTOWANIE HIPOTEZ STATYSTYCZNYCH
STATYSTYKA MATEMATYCZNA WYKŁAD 4. WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X.
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
STATYSTYKA MATEMATYCZNA WYKŁAD 4 WERYFIKACJA HIPOTEZ PARAMETRYCZNYCH X - cecha populacji, θ parametr rozkładu cechy X. Wysuwamy hipotezy: zerową (podstawową H ( θ = θ i alternatywną H, która ma jedną z
ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH
 1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
1 ALGORYTMICZNA I STATYSTYCZNA ANALIZA DANYCH WFAiS UJ, Informatyka Stosowana II stopień studiów 2 Wnioskowanie statystyczne dla zmiennych numerycznych Porównywanie dwóch średnich Boot-strapping Analiza
Jak sprawdzić normalność rozkładu w teście dla prób zależnych?
 Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
Jak sprawdzić normalność rozkładu w teście dla prób zależnych? W pliku zalezne_10.sta znajdują się dwie zmienne: czasu biegu przed rozpoczęciem cyklu treningowego (zmienna 1) oraz czasu biegu po zakończeniu
ZMIENNE LOSOWE. Zmienna losowa (ZL) X( ) jest funkcją przekształcającą przestrzeń zdarzeń elementarnych w zbiór liczb rzeczywistych R 1 tzn. X: R 1.
 X( ) jest funkcją przekształcającą przestrzeń zdarzeń elementarnych w zbiór liczb rzeczywistych R 1 tzn. X: R 1.") Opracowała: Joanna Kisielińska ZMIENNE LOSOWE Zmienna losowa (ZL) X( ) jest funkcją przekształcającą przestrzeń zdarzeń elementarnych w zbiór liczb rzeczywistych R tzn. X: R. Realizacją zmiennej losowej
Opracowała: Joanna Kisielińska ZMIENNE LOSOWE Zmienna losowa (ZL) X( ) jest funkcją przekształcającą przestrzeń zdarzeń elementarnych w zbiór liczb rzeczywistych R tzn. X: R. Realizacją zmiennej losowej
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria Wykład 5 dr inż. Anna Skowrońska-Szmer zima 2017/2018 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją
Statystyka matematyczna i ekonometria Wykład 5 dr inż. Anna Skowrońska-Szmer zima 2017/2018 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją
1 Podstawy rachunku prawdopodobieństwa
 1 Podstawy rachunku prawdopodobieństwa Dystrybuantą zmiennej losowej X nazywamy prawdopodobieństwo przyjęcia przez zmienną losową X wartości mniejszej od x, tzn. F (x) = P [X < x]. 1. dla zmiennej losowej
1 Podstawy rachunku prawdopodobieństwa Dystrybuantą zmiennej losowej X nazywamy prawdopodobieństwo przyjęcia przez zmienną losową X wartości mniejszej od x, tzn. F (x) = P [X < x]. 1. dla zmiennej losowej
Rachunek prawdopodobieństwa i statystyka - W 9 Testy statystyczne testy zgodności. Dr Anna ADRIAN Paw B5, pok407
 Rachunek prawdopodobieństwa i statystyka - W 9 Testy statystyczne testy zgodności Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Weryfikacja hipotez dotyczących postaci nieznanego rozkładu -Testy zgodności.
Rachunek prawdopodobieństwa i statystyka - W 9 Testy statystyczne testy zgodności Dr Anna ADRIAN Paw B5, pok407 adan@agh.edu.pl Weryfikacja hipotez dotyczących postaci nieznanego rozkładu -Testy zgodności.
Statystyka matematyczna i ekonometria
 Statystyka matematyczna i ekonometria Wykład 5 Anna Skowrońska-Szmer lato 2016/2017 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją jako prawdziwą
Statystyka matematyczna i ekonometria Wykład 5 Anna Skowrońska-Szmer lato 2016/2017 Hipotezy 2 Hipoteza zerowa (H 0 )- hipoteza o wartości jednego (lub wielu) parametru populacji. Traktujemy ją jako prawdziwą
1. Opis tabelaryczny. 2. Graficzna prezentacja wyników. Do technik statystyki opisowej można zaliczyć:
 Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wprowadzenie Statystyka opisowa to dział statystyki zajmujący się metodami opisu danych statystycznych (np. środowiskowych) uzyskanych podczas badania statystycznego (np. badań terenowych, laboratoryjnych).
Wnioskowanie statystyczne. Statystyka w 5
 Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Wnioskowanie statystyczne tatystyka w 5 Rozkłady statystyk z próby Próba losowa pobrana z populacji stanowi realizacje zmiennej losowej jak ciąg zmiennych losowych (X, X,... X ) niezależnych i mających
Statystyki: miary opisujące rozkład! np. : średnia, frakcja (procent), odchylenie standardowe, wariancja, mediana itd.
, odchylenie standardowe, wariancja, mediana itd.") Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Wnioskowanie statystyczne obejmujące metody pozwalające na uogólnianie wyników z próby na nieznane wartości parametrów oraz szacowanie błędów tego uogólnienia. Przewidujemy nieznaną wartości parametru
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć)
") Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Szczegółowy program kursu Statystyka z programem Excel (30 godzin lekcyjnych zajęć) 1. Populacja generalna a losowa próba, parametr rozkładu cechy a jego ocena z losowej próby, miary opisu statystycznego
Zadanie 1. Analiza Analiza rozkładu
 Zadanie 1 data lab.zad 1; input czas; datalines; 85 3060 631 819 805 835 955 595 690 73 815 914 ; run; Analiza Analiza rozkładu Ponieważ jesteśmy zainteresowani wyznaczeniem przedziału ufności oraz weryfikacja
Zadanie 1 data lab.zad 1; input czas; datalines; 85 3060 631 819 805 835 955 595 690 73 815 914 ; run; Analiza Analiza rozkładu Ponieważ jesteśmy zainteresowani wyznaczeniem przedziału ufności oraz weryfikacja
Statystyczna analiza danych
 Statystyczna analiza danych Testowanie hipotez statystycznych Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/23 Testowanie hipotez średniej w R Test istotności dla wartości
Statystyczna analiza danych Testowanie hipotez statystycznych Ewa Szczurek szczurek@mimuw.edu.pl Instytut Informatyki Uniwersytet Warszawski 1/23 Testowanie hipotez średniej w R Test istotności dla wartości
STATYSTYKA MATEMATYCZNA WYKŁAD 4. Testowanie hipotez Estymacja parametrów
 STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
STATYSTYKA MATEMATYCZNA WYKŁAD 4 Testowanie hipotez Estymacja parametrów WSTĘP 1. Testowanie hipotez Błędy związane z testowaniem hipotez Etapy testowana hipotez Testowanie wielokrotne 2. Estymacja parametrów
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych
 Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
Zadania ze statystyki, cz.7 - hipotezy statystyczne, błąd standardowy, testowanie hipotez statystycznych Zad. 1 Średnia ocen z semestru letniego w populacji studentów socjologii w roku akademickim 2011/2012
TESTOWANIE HIPOTEZ STATYSTYCZNYCH
 TETOWANIE HIPOTEZ TATYTYCZNYCH HIPOTEZA TATYTYCZNA przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Prawdziwość tego przypuszczenia jest oceniana na
TETOWANIE HIPOTEZ TATYTYCZNYCH HIPOTEZA TATYTYCZNA przypuszczenie co do rozkładu populacji generalnej (jego postaci funkcyjnej lub wartości parametrów). Prawdziwość tego przypuszczenia jest oceniana na
12/30/2018. Biostatystyka, 2018/2019 dla Fizyki Medycznej, studia magisterskie. Estymacja Testowanie hipotez
 Biostatystyka, 2018/2019 dla Fizyki Medycznej, studia magisterskie Wyznaczanie przedziału 95%CI oznaczającego, że dla 95% prób losowych następujące nierówności są prawdziwe: X t s 0.025 n < μ < X + t s
Biostatystyka, 2018/2019 dla Fizyki Medycznej, studia magisterskie Wyznaczanie przedziału 95%CI oznaczającego, że dla 95% prób losowych następujące nierówności są prawdziwe: X t s 0.025 n < μ < X + t s
dr hab. Dariusz Piwczyński, prof. nadzw. UTP
 dr hab. Dariusz Piwczyński, prof. nadzw. UTP Porównanie większej niż 2 liczby grup (k>2) Zmienna zależna skala przedziałowa Zmienna niezależna skala nominalna lub porządkowa 2 Istota teorii analizy wariancji
dr hab. Dariusz Piwczyński, prof. nadzw. UTP Porównanie większej niż 2 liczby grup (k>2) Zmienna zależna skala przedziałowa Zmienna niezależna skala nominalna lub porządkowa 2 Istota teorii analizy wariancji
Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: y t. X 1 t. Tabela 1.
 tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
tel. 44 683 1 55 tel. kom. 64 566 811 e-mail: biuro@wszechwiedza.pl Zadanie 1 Zakładając liniową relację między wydatkami na obuwie a dochodem oszacować MNK parametry modelu: gdzie: y t X t y t = 1 X 1
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI. Test zgodności i analiza wariancji Analiza wariancji
 WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI Test zgodności i analiza wariancji Analiza wariancji Test zgodności Chi-kwadrat Sprawdza się za jego pomocą ZGODNOŚĆ ROZKŁADU EMPIRYCZNEGO Z PRÓBY Z ROZKŁADEM HIPOTETYCZNYM
WIELKA SGH-OWA POWTÓRKA ZE STATYSTYKI Test zgodności i analiza wariancji Analiza wariancji Test zgodności Chi-kwadrat Sprawdza się za jego pomocą ZGODNOŚĆ ROZKŁADU EMPIRYCZNEGO Z PRÓBY Z ROZKŁADEM HIPOTETYCZNYM
Odchudzamy serię danych, czyli jak wykryć i usunąć wyniki obarczone błędami grubymi
 Odchudzamy serię danych, czyli jak wykryć i usunąć wyniki obarczone błędami grubymi Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska D syst D śr m 1 3 5 2 4 6 śr j D 1
Odchudzamy serię danych, czyli jak wykryć i usunąć wyniki obarczone błędami grubymi Piotr Konieczka Katedra Chemii Analitycznej Wydział Chemiczny Politechnika Gdańska D syst D śr m 1 3 5 2 4 6 śr j D 1
dr hab. Dariusz Piwczyński, prof. nadzw. UTP
 dr hab. Dariusz Piwczyński, prof. nadzw. UTP NIEZBĘDNE DO ZROZUMIENIA WYKŁADU POJĘCIA Doświadczenie jednogrupowe (jednopróbkowe), dwugrupowe (dwupróbkowe) Doświadczenie niezależne i wiązane (zależne, sparowane)
dr hab. Dariusz Piwczyński, prof. nadzw. UTP NIEZBĘDNE DO ZROZUMIENIA WYKŁADU POJĘCIA Doświadczenie jednogrupowe (jednopróbkowe), dwugrupowe (dwupróbkowe) Doświadczenie niezależne i wiązane (zależne, sparowane)
Importowanie danych do SPSS Eksportowanie rezultatów do formatu MS Word... 22
 Spis treści Przedmowa do wydania pierwszego.... 11 Przedmowa do wydania drugiego.... 15 Wykaz symboli.... 17 Litery alfabetu greckiego wykorzystywane w podręczniku.... 17 Symbole wykorzystywane w zagadnieniach
Spis treści Przedmowa do wydania pierwszego.... 11 Przedmowa do wydania drugiego.... 15 Wykaz symboli.... 17 Litery alfabetu greckiego wykorzystywane w podręczniku.... 17 Symbole wykorzystywane w zagadnieniach